Sec 섹션 개발 가이드라인
Sec 섹션은 DevSecOps의 “Sec” 부분으로 GitLab 애플리케이션 보안 기능을 담당합니다. Sec 섹션에 특정한 개발 가이드는 여기 나열되어 있습니다.
용어를 참고하여 우리의 공유 용어를overview 확인하세요.
아키텍처
개요
보안 기능을 지원하는 아키텍처는 두 가지 주요 부분으로 나뉩니다:
- 스캐닝
- 처리, 시각화 및 관리
스캐닝
스캐닝 부분은 주어진 리소스에서 취약점을 찾아내고 결과를 내보내는 역할을 담당합니다. 스캔은 Analyzers라는 여러 작은 프로젝트를 통해 CI/CD 작업에서 실행됩니다. 이들은 우리의 Analyzers 서브그룹에서 찾을 수 있습니다.
Analyzers는 GitLab에 통합하기 위해 내부 또는 외부에서 개발된 보안 도구인 Scanners 주위에 래핑된 것입니다.
Analyzers는 주로 Go로 작성되어 있습니다.
일부 제3자 통합자는 우리의 통합 문서를 따름으로써 추가 Scanners를 제공합니다. 이는 동일한 아키텍처를 활용합니다.
스캔 결과는 Secure report format에 준수해야 하는 JSON 보고서로 내보내지며, 파이프라인 작업이 완료된 후 처리 가능하도록 CI/CD 작업 보고서 아티팩트로 업로드됩니다.
처리, 시각화 및 관리
데이터가 보고서 아티팩트로 사용할 수 있게 된 후, GitLab Rails 애플리케이션에 의해 처리되어 우리의 보안 기능을 활성화할 수 있습니다. 여기에는 다음이 포함됩니다:
- 보안 대시보드, 머지 요청 위젯, 파이프라인 뷰 등.
- 취약점과의 상호작용.
- 승인 규칙.
맥락에 따라, 보안 보고서는 데이터베이스에 저장되거나 요구에 따라 보고서 아티팩트로 남아있을 수 있습니다.
보안 보고서 수집 개요
스캐너가 생성한 보고서를 GitLab이 처리하는 방식에 대한 자세한 내용은 보안 보고서 수집 개요를 참조하세요.
CI/CD 템플릿 개발
CI/CD 템플릿은 Verify 섹션의 책임이지만, 많은 템플릿이 Sec 섹션의 기능 사용에 중요합니다.
CI/CD 템플릿을 다루고 있다면 GitLab CI/CD 템플릿 개발 가이드를 읽어보세요.
기본 식별자의 중요성
분석기 JSON 보고서 내의 identifiers 필드는 취약점을 설명하는 데 사용되는 유형 및 범주의 모음을 포함합니다(즉, CWE 패밀리).
identifiers 컬렉션의 첫 번째 항목은 기본 식별자로 알려져 있으며, 이는 취약점을 설명하고 추적하는 데 필수적인 요소입니다.
대부분의 경우, identifiers 컬렉션은 순서가 없으며 나머지 보조 식별자는 취약점을 그룹화하기 위한 메타데이터로 작용합니다(예외는 분석기 취약점 번역 참조).
기본 식별자가 변경되고 프로젝트 파이프라인이 다시 실행되면, 새로운 보고서를 수집하면 이전 데이터베이스 레코드가 “고아”가 됩니다.
우리의 처리 논리는 두 개의 다른 취약점의 델타를 생성하는 것에 의존하므로, 다소 혼란스러워 보일 수 있습니다. 예를 들면:
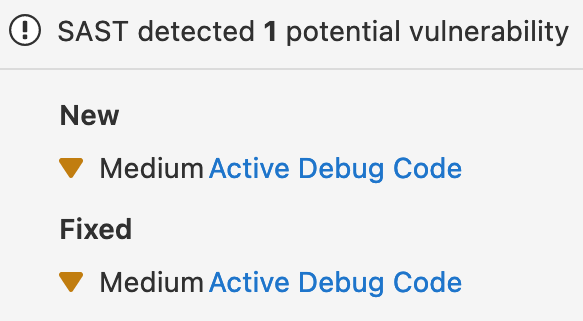
병합된 후, 이전 취약점은 “수정됨”으로 나열되며, 도입된 것은 “탐지됨”으로 나열됩니다.
주요 식별자 안정성을 보장하기 위한 지침 원칙
-
주요 식별자는 그럴듯한 이유가 없는 한 결코 변경되지 않아야 합니다.
-
취약성 변환을 지원하는 분석기는 결과의 “고아화”를 방지하기 위해 레거시 주요 식별자를 보조 위치에 포함해야 합니다.
-
주요 식별자를 넘어 보조 식별자의 순서는 중요하지 않습니다.
-
식별자는
Type및Value필드의 조합을 기반으로 고유합니다 (자세한 내용은 식별자 지문을 참조하세요). -
주요 식별자를 변경하면 이전 버전의 분석기 롤백으로 고아화된 결과를 수정할 수 없습니다. 이전에 데이터베이스에 수집된 데이터는 데이터 마이그레이션을 자동화할 수 있는 방법이 거의 없는 이전 작업의 유물입니다.
분석기 취약성 변환
SAST Semgrep 분석기의 경우, 특별히 중요한 보조 식별자가 있습니다: 보고서의 취약성을 레거시 분석기(즉, bandit 또는 ESLint)에 연결하는 식별자입니다.
취약성 변환을 활성화하기 위해 Semgrep 분석기는 레거시 분석기의 주요 식별자와 정확히 일치하는 보조 식별자에 의존합니다.
예를 들어, eslint가 이전에 취약성 기록을 생성하는 데 사용되었을 때,
semgrep 분석기는 원본 ESLint 주요 식별자를 포함하는 식별자 컬렉션을 생성해야 합니다.
원본 eslint 보고서는 다음과 같습니다:
{
"version": "14.0.4",
"vulnerabilities": [
{
"identifiers": [
{
"type": "eslint_rule_id",
"name": "ESLint rule ID security/detect-eval-with-expression",
"value": "security/detect-eval-with-expression"
}
]
}
]
}
해당하는 Semgrep 보고서는 eslint_rule_id를 포함해야 합니다:
{
"version": "14.0.4",
"vulnerabilities": [
{
"identifiers": [
{
"type": "semgrep_id",
"name": "eslint.detect-eval-with-expression",
"value": "eslint.detect-eval-with-expression",
"url": "https://semgrep.dev/r/gitlab.eslint.detect-eval-with-expression"
},
{
"type": "eslint_rule_id",
"name": "ESLint rule ID security/detect-eval-with-expression",
"value": "security/detect-eval-with-expression"
}
]
}
]
}
취약성 추적은 두 식별자의 조합에 의존하여 이전 레거시 분석기로 생성된 데이터베이스 기록을 새로운 semgrep로 생성된 것에 다시 매핑합니다.
 도움말
도움말