보안 스캐너 통합
GitLab에 보안 스캐너를 통합하는 것은 사용자가 GitLab 프로젝트를 스캔하기 위해 CI/CD 구성 파일에 추가할 수 있는 CI/CD 작업 정의를 제공하는 것으로 구성됩니다.
이 작업은 GitLab에서 지정한 형식으로 결과를 출력해야 합니다.
이 결과는 파이프라인 보기, 병합 요청 위젯, 보안 대시보드와 같이 GitLab의 여러 곳에 자동으로 표시됩니다.
스캔 작업은 일반적으로 스캐너와 모든 종속성을 포함한 Docker 이미지를 기반으로 하는 독립 실행형 환경에서 실행됩니다.
이 페이지는 보안 스캐너를 구현하는 CI/CD 작업을 작성하기 위한 요구 사항 및 지침과 Docker 이미지에 대한 요구 사항 및 지침을 문서화합니다.
작업 정의
이 섹션에서는 보안 스캐너의 작업 정의 파일에 추가해야 하는 여러 중요한 필드를 설명합니다.
이러한 필드와 기타 사용 가능한 필드에 대한 전체 문서는 CI 문서에서 볼 수 있습니다.
이름
일관성을 위해 스캔 작업은 스캐너의 이름을 소문자로 사용해야 합니다.
작업 이름은 스캐닝 유형 뒤에 접미사가 붙습니다:
_dependency_scanning_container_scanning_dast_sast
예를 들어 “MySec” 스캐너를 기반으로 한 의존성 스캔 작업은 mysec_dependency_scanning이라고 할 수 있습니다.
이미지
image 키워드는
보안 스캐너를 포함하는
Docker 이미지를 지정하는 데 사용됩니다.
스크립트
script 키워드는
스캐너를 실행하기 위한 명령을 지정하는 데 사용됩니다.
script 항목은 비워둘 수 없으므로 스캔을 수행하는 명령으로 설정해야 합니다.
자동으로 스캔을 수행하기 위해 Docker 이미지의
미리 정의된 ENTRYPOINT와 CMD에 의존하는 것은 불가능합니다.
before_script를
작업 정의에서 사용하는 것은 피해야 합니다.
사용자가 스캔 수행 전에 프로젝트를 준비하기 위해 의존할 수 있기 때문입니다.
예를 들어, SAST 또는 의존성 스캔을 수행하기 전에
특정 프로젝트에 필요한 시스템 라이브러리를 설치하기 위해 before_script를 사용하는 것이 일반적입니다.
유사하게, after_script를
작업 정의에서 사용하는 것은 피해야 합니다.
사용자가 이를 재정의할 수 있기 때문입니다.
단계
일관성을 위해 가능할 경우 스캔 작업은 test 단계에 속해야 합니다.
stage 키워드는 생략할 수 있습니다.
test는 기본값이기 때문입니다.
오류 방지
기본적으로 스캔 작업은 실패할 때 파이프라인을 차단하지 않습니다.
따라서 allow_failure 매개변수는 true로 설정해야 합니다.
아티팩트
스캔 작업은 수행하는 스캔 유형에 해당하는 보고서를 선언해야 하며,
artifacts:reports 키워드를 사용해야 합니다.
유효한 보고서는 다음과 같습니다:
dependency_scanningcontainer_scanningdastapi_fuzzingcoverage_fuzzingsast
예를 들어, 다음은 gl-sast-report.json이라는 파일을 생성하여 SAST 보고서로 업로드하는
SAST 작업의 정의입니다:
mysec_sast:
image: registry.gitlab.com/secure/mysec
artifacts:
reports:
sast: gl-sast-report.json
gl-sast-report.json은 예시 파일 경로이지만 다른 파일 이름도 사용할 수 있습니다.
자세한 내용은 출력 파일 섹션을 참조하세요.
이것은 작업 정의에서 reports:sast 키 아래에 선언되었기 때문에 SAST 보고서로 처리됩니다.
파일 이름과는 무관합니다.
정책
특정 GitLab 워크플로, 예를 들어 AutoDevOps는 주어진 스캔이 비활성화되어야 함을 나타내기 위해 CI/CD 변수를 정의합니다. 이를 확인하기 위해서는 다음과 같은 변수를 확인할 수 있습니다:
DEPENDENCY_SCANNING_DISABLEDCONTAINER_SCANNING_DISABLEDSAST_DISABLEDDAST_DISABLED
스캐너 유형에 따라 적절하다면, 사용자 정의 스캐너의 실행을 비활성화해야 합니다.
GitLab은 또한 리포지토리의 언어 목록을 제공하는 CI_PROJECT_REPOSITORY_LANGUAGES 변수를 정의합니다. 이 값에 따라 스캐너가 다르게 동작할 수 있습니다.
언어 감지는 현재 linguist Ruby 젬에 의존하고 있습니다.
미리 정의된 CI/CD 변수를 참조하세요.
정책 확인 예시
이 예시는 프로젝트 리포지토리에 Java 소스 코드가 포함되어 있고 dependency_scanning 기능이 활성화되지 않은 경우,
사용자 정의 Dependency Scanning 작업인 mysec_dependency_scanning을 건너뛰는 방법을 보여줍니다:
mysec_dependency_scanning:
rules:
- if: $DEPENDENCY_SCANNING_DISABLED == 'true'
when: never
- if: $GITLAB_FEATURES =~ /\bdependency_scanning\b/
exists:
- '**/*.java'
추가적인 작업 정책은 사용자의 필요에 따라서만 구성되어야 합니다.
예를 들어, 미리 정의된 정책은 특정 브랜치에 대해 스캔 작업을 트리거하지 않거나 특정 파일 집합이 변경될 때는 트리거하지 않아야 합니다.
도커 이미지
도커 이미지는 스캐너와 그에 의존하는 모든 라이브러리 및 도구를 결합한 독립된 환경입니다.
스캐너를 도커 이미지로 패키징하면 그 의존성과 구성 요소가 항상 존재하게 되어, 스캐너가 실행되는 개별 머신과 상관없이 사용할 수 있습니다.
이미지 크기
CI 인프라에 따라, CI는 작업이 실행될 때마다 도커 이미지를 가져와야 할 수 있습니다.
스캔 작업이 빠르게 실행되고 대역폭 낭비를 피하기 위해서 도커 이미지는 가능한 한 작아야 합니다.
50MB 이하를 목표로 해야 하며, 불가능한 경우에는 1.46GB 이하로 유지해야 합니다. 이는 DVD-ROM의 크기입니다.
스캐너가 완전한 Linux 환경을 요구하는 경우, Debian “slim” 배포판 또는 Alpine Linux를 사용하는 것이 좋습니다.
가능하다면 FROM scratch 지침을 사용하여 이미지를 처음부터 구축하고, 필요한 모든 라이브러리로 스캐너를 컴파일하는 것이 좋습니다.
다단계 빌드도 이미지를 작게 유지하는 데 도움이 될 수 있습니다.
이미지 크기를 작게 유지하기 위해 dive를 사용하여 도커 이미지의 레이어를 분석하여 추가적인 부풀음이 발생하는 곳을 식별하는 것을 고려하세요.
일부 경우에는 이미지에서 파일을 제거하기 어려울 수 있습니다. 이러한 경우에는 Zstandard를 사용하여 파일이나 대용량 디렉토리를 압축하는 것을 고려합니다.
Zstandard는 압축 수준이 다양하여 이미지 크기를 줄이면서도 압축 해제 속도에 거의 영향을 미치지 않습니다.
이미지가 시작되는 즉시 압축된 디렉토리를 자동으로 압축 해제하는 것이 도움이 될 수 있습니다.
이는 도커 이미지의 /etc/bashrc 또는 특정 사용자의 $HOME/.bashrc에 단계를 추가하여 수행할 수 있습니다.
후자의 경우, bash 로그인 셸을 실행하도록 항목 진입점을 변경해야 합니다.
시작을 위해 몇 가지 예시는 다음과 같습니다:
- https://gitlab.com/gitlab-org/security-products/license-management/-/blob/0b976fcffe0a9b8e80587adb076bcdf279c9331c/config/install.sh#L168-170
- https://gitlab.com/gitlab-org/security-products/license-management/-/blob/0b976fcffe0a9b8e80587adb076bcdf279c9331c/config/.bashrc#L49
이미지 태그
Docker 공식 이미지 프로젝트에 문서화된 바와 같이,
버전 번호 태그에 별명을 부여하는 것을 강력히 권장합니다.
이렇게 하면 사용자가 특정 시리즈의 “가장 최근” 릴리스를 쉽게 참조할 수 있습니다.
Docker 태깅: Docker 이미지의 태깅 및 버전 관리를 위한 모범 사례도 참조하세요.
커맨드 라인
스캐너는 환경 변수를 입력으로 받아들이는 커맨드 라인 도구로,
잡 정의를 기반으로 보고서로 업로드되는 파일을 생성합니다.
또한 표준 출력 및 표준 오류 스트림에 텍스트 출력을 생성하고 상태 코드로 종료합니다.
변수
모든 CI/CD 변수는 환경 변수로 스캐너에 전달됩니다.
스캔된 프로젝트는 미리 정의된 CI/CD 변수로 설명됩니다.
SAST 및 종속성 스캐닝
SAST 및 종속성 스캐닝 스캐너는 CI_PROJECT_DIR CI/CD 변수로 제공된 프로젝트 디렉토리의 파일을 스캔해야 합니다.
컨테이너 스캐닝
GitLab의 공식 컨테이너 스캐닝과 일관되게 하기 위해,
스캐너는 CI_APPLICATION_REPOSITORY 및 CI_APPLICATION_TAG로 제공된 이름과 태그의 Docker 이미지를 스캔해야 합니다.
DOCKER_IMAGE CI/CD 변수가 제공되는 경우, CI_APPLICATION_REPOSITORY 및 CI_APPLICATION_TAG 변수는 무시되며,
대신 DOCKER_IMAGE 변수로 지정된 이미지가 스캔됩니다.
제공되지 않은 경우, CI_APPLICATION_REPOSITORY는
$CI_REGISTRY_IMAGE/$CI_COMMIT_REF_SLUG로 기본 설정되어야 하며, 이는 미리 정의된 CI/CD 변수의 조합입니다.
CI_APPLICATION_TAG는 CI_COMMIT_SHA로 기본 설정되어야 합니다.
스캐너는 DOCKER_USER 및 DOCKER_PASSWORD 변수를 사용하여 Docker 레지스트리에 로그인해야 합니다.
이들이 정의되지 않은 경우, 스캐너는 기본값으로 CI_REGISTRY_USER 및 CI_REGISTRY_PASSWORD를 사용해야 합니다.
구성 파일
스캐너가 특정 구성 파일을 로드하기 위해 CI_PROJECT_DIR를 사용할 수 있으나,
구성 파일이 아닌 CI/CD 변수로 구성 사항을 노출하는 것이 권장됩니다.
출력 파일
GitLab CI/CD에 업로드되는 모든 아티팩트와 마찬가지로,
스캐너에 의해 생성된 보안 보고서는 CI_PROJECT_DIR CI/CD 변수로 제공된 프로젝트 디렉토리에 작성되어야 합니다.
출력 파일은 스캐닝 유형에 따라 명명하는 것이 좋으며, gl-를 접두사로 사용하는 것이 좋습니다.
모든 보안 보고서는 JSON 파일이므로, 파일 확장자로 .json을 사용하는 것이 좋습니다.
예를 들어, 종속성 스캐닝 보고서에 대한 제안된 파일 이름은 gl-dependency-scanning.json입니다.
잡 정의의 artifacts:reports 키워드는
보안 보고서가 작성되는 파일 경로와 일치해야 합니다.
예를 들어, 종속성 스캐닝 분석기가 CI 프로젝트 디렉토리에 보고서를 작성하고,
이 보고서 파일 이름이 depscan.json이라면, artifacts:reports:dependency_scanning은 depscan.json으로 설정해야 합니다.
종료 코드
POSIX 종료 코드 표준에 따라, 스캐너는 성공 시 0을, 실패 시 1을 반환합니다.
성공에는 취약점이 발견된 경우도 포함됩니다.
CI 잡이 실패하는 경우, 보안 보고서 결과는 GitLab에 수집되지 않습니다,
비록 잡이 실패 허용을 한다고 하더라도 말입니다.
그러나 보고서 아티팩트는 여전히 GitLab에 업로드되며,
파이프라인 보안 탭에서 다운로드할 수 있습니다.
로깅
스캐너는 오류 메시지와 경고를 기록해야 하며, 이를 통해 사용자는 CI 스캔 작업의 로그를 확인하여 구성 오류 및 통합 문제를 쉽게 조사할 수 있습니다.
스캐너는 ANSI 이스케이프 코드를 사용하여 Unix 표준 출력 및 표준 오류 스트림에 작성하는 메시지에 색상을 입힐 수 있습니다.
오류를 보고할 때는 빨간색, 경고에 대해선 노란색, 공지사항에는 초록색을 사용하는 것을 권장합니다.
또한 오류 메시지는 [ERRO]로 접두사를 붙이고, 경고는 [WARN], 공지사항은 [INFO]로 접두사를 붙이는 것을 권장합니다.
로깅 수준
스캐너는 SECURE_LOG_LEVEL CI/CD 변수에 설정된 로그 수준보다 낮은 로그 메시지는 필터링해야 합니다.
예를 들어, SECURE_LOG_LEVEL이 error로 설정된 경우 info 및 warn 메시지는 건너뛰어야 합니다.
허용되는 값은 다음과 같으며, 높은 수준에서 낮은 수준으로 나열됩니다:
fatalerrorwarninfodebug
디버깅에 유용할 수 있는 상세한 로깅을 위해 debug 수준의 사용을 권장합니다.
SECURE_LOG_LEVEL의 기본값은 info로 설정되어야 합니다.
명령줄을 실행할 때, 스캐너는 명령줄 및 해당 출력을 로깅하기 위해 debug 수준을 사용해야 합니다.
명령줄이 실패할 경우, error 로그 수준으로 기록되어야 하며, 이렇게 하면 로그 수준을 debug로 변경하고 스캔 작업을 다시 실행하지 않고도 문제를 디버깅할 수 있습니다.
일반 logutil 패키지
Logrus 및 common의 logutil 패키지을 사용하여
Logrus의 포매터를 구성할 것을 권장합니다.
logutil README를 참조하세요.
보고서
보고서는 취약점과 가능한 수정 사항을 통합한 JSON 문서입니다.
이 문서는 통합자가 필드를 설정하는 데 도움이 되는 보고서 JSON 형식, 권장 사항 및 예제를 제공합니다.
형식은 SAST, DAST, Dependency Scanning, 및 Container Scanning 문서에 자세히 설명되어 있습니다.
이 스캐너들의 스키마는 다음에서 확인할 수 있습니다:
보고서 검증
- 소개됨 GitLab 15.0에서.
스캐너에 의해 생성된 보고서가 보고서에 선언된 스키마 버전과의 검증을 통과하는지 확인해야 합니다.
검증을 통과하지 않은 보고서는 GitLab에 수집되지 않으며, 해당 파이프라인에 오류 메시지가 표시됩니다.
보안 보고서 스키마의 사용 중단된 버전을 사용하는 보고서는 수집되지만 해당 파이프라인에 경고 메시지가 표시됩니다. 이 경고가 표시되면 최신 사용 가능한 스키마를 사용하도록 분석기를 업데이트하세요.
스키마 버전의 사용 중단 기간이 지나면 해당 파일은 GitLab에서 제거됩니다. 제거된 버전을 선언한 보고서는 거부되며, 해당 파이프라인에 오류 메시지가 표시됩니다.
보고서가 어떤 공급된 스키마 버전과도 일치하지 않는 PATCH 버전을 사용하는 경우, 최신 공급된 PATCH 버전과 대조하여 검증됩니다. 예를 들어, 보고서 버전이 15.0.23이고 최신 공급 버전이 15.0.6인 경우, 보고서는 버전 15.0.6과 대조하여 검증됩니다.
GitLab은
json_schemer gem을 사용하여 검증을 수행합니다.
보고서 검증에 대한 지속적인 개선 사항은 이 에픽에서 추적됩니다.
그동안 어떤 버전이 지원되는지 소스 코드에서 확인할 수 있습니다.
귀하의 인스턴스에 적합한 버전을 선택하는 것을 잊지 마세요. 예를 들어 v15.7.3-ee.
로컬에서 검증
GitLab에서 분석기를 실행하기 전에, 분석기가 생성한 보고서가 선언된 스키마 버전을 준수하는지 검증해야 합니다.
아래 스크립트를 사용하여 지정된 스키마에 대해 JSON 파일을 검증하세요.
require 'bundler/inline'
gemfile do
source 'https://rubygems.org'
gem 'json_schemer'
end
require 'json'
require 'pathname'
raise 'Usage: ruby script.rb <security schema filename> <report filename>' unless ARGV.size == 2
schema = JSONSchemer.schema(Pathname.new(ARGV[0]))
report = JSON.parse(File.open(ARGV[1]).read)
schema_validation_errors = schema.validate(report).map { |error| JSONSchemer::Errors.pretty(error) }
puts(schema_validation_errors)
-
보고서 유형 및 선언된 버전과 일치하는 적절한 스키마를 다운로드합니다. 예를 들어, 버전
15.0.6의container_scanning보고서 스키마를https://gitlab.com/gitlab-org/security-products/security-report-schemas/-/raw/v15.0.6/dist/container-scanning-report-format.json?inline=false에서 찾을 수 있습니다. -
위의 Ruby 스크립트를 파일에 저장합니다. 예:
validate.rb. - 스크립트를 실행하고, 스키마 및 보고서 파일 이름을 인수로 전달합니다. 예를 들어:
-
로컬 Ruby 인터프리터 사용:
ruby validate.rb container-scanning-format_15-0-6.json gl-container-scanning-report.json. -
Docker 사용:
docker run -it --rm -v $(pwd):/ci ruby:3 ruby /ci/validate.rb /ci/container-scanning-format_15-0-6.json /ci/gl-container-scanning-report.json.
-
- 검증 오류가 화면에 표시됩니다. GitLab이 귀하의 보고서를 수집할 수 있도록 이 오류를 해결해야 합니다.
보고서 필드
버전
이 필드는 사용 중인 보안 보고서 스키마 버전을 지정합니다. 사용할 버전 정보는 릴리스를 참조하세요.
GitLab은 이 값으로 지정된 스키마 버전에 대해 보고서를 검증합니다.
GitLab에서 지원하는 버전은
gitlab/ee/lib/ee/gitlab/ci/parsers/security/validators/schemas에서 확인할 수 있습니다.
취약점
보고서의 vulnerabilities 필드는 취약점 객체의 배열입니다.
ID
id 필드는 취약점의 고유 식별자입니다.
이는 리미디에이션 객체에서 수정된 취약점을 참조하는 데 사용됩니다.
UUID를 생성하고 이를 id 필드의 값으로 사용하는 것이 좋습니다.
카테고리
category 필드의 값은 보고서 유형과 일치합니다:
dependency_scanningcontainer_scanningsastdast
스캔
scan 필드는 스캔 자체에 대한 메타 정보를 포함하는 객체입니다: 스캔을 수행한 analyzer
와 scanner, 스캔이 실행된 start_time 및 end_time, 그리고 스캔의 status (“success” 또는 “failure”).
analyzer 및 scanner 필드는 사람이 읽을 수 있는 name과 기술적인 id를 포함하는 객체입니다.
id는 다른 통합자가 제공하는 다른 분석기 또는 스캐너와 중복되지 않아야 합니다.
스캔 기본 식별자
scan.primary_identifiers 필드는
기본 식별자 배열을 포함하는 선택적 필드입니다.
이는 분석기가 스캔을 수행한 모든 규칙 세트의 포괄적인 목록입니다.
주어진 스캔의 Vulnerabilities 배열이 비어 있을 수 있지만, 이 선택적 필드는
Rails 애플리케이션에 실행된 규칙을 알리기 위해 모든 잠재적 식별자의 완전한 목록을 포함해야 합니다.
채워진 경우, Rails 애플리케이션은 이전 탐지된 취약점을 자동으로 해결할 수 있습니다. 이는 기본 식별자가 포함되지 않았을 때 더 이상 관련이 없도록 설정됩니다.
이름, 메시지 및 설명
name 및 message 필드는 취약점에 대한 간단한 설명을 포함합니다.
description 필드는 더 많은 세부 정보를 제공합니다.
name 필드는 맥락이 없으며 취약점이 발견된 위치에 대한 정보를 포함하지 않지만,
message는 위치를 반복할 수 있습니다.
시각적 예로, 이 스크린샷은 파이프라인 보기에서 취약점을 볼 때 이러한 필드가 사용되는 위치를 강조합니다.
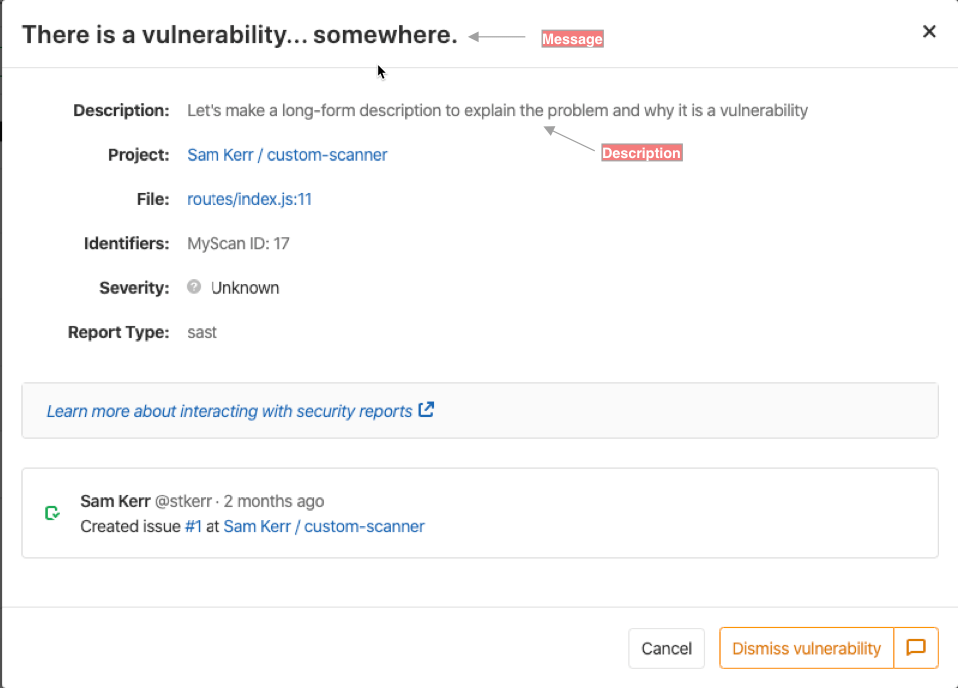
예를 들어, Dependency Scanning에서 보고된 취약점의 message는 취약한 종속성에 대한 정보를 제공하며,
이는 취약점의 location 필드와 중복됩니다.
name 필드가 더 선호되지만, 맥락/위치를 제목에서 제거할 수 없는 경우 message 필드가 사용됩니다.
설명을 위해, Dependency Scanning 스캐너에 의해 보고된 예제 취약점 객체와, message가 location 필드를 반복하는 위치는 다음과 같습니다:
{
"location": {
"dependency": {
"package": {
"name": "debug"
}
}
},
"name": "정규 표현식 서비스 거부",
"message": "debug에서 정규 표현식 서비스 거부",
"description": "debug 모듈은 신뢰되지 않은 사용자 입력이 `o` 포맷터로 전달될 때 정규 표현식 서비스 거부에 취약합니다.
2초 동안 차단되려면 약 50k 문자가 필요하여 심각도가 낮은 문제입니다."
}
description은 취약점이 작동하는 방식이나 익스플로잇에 대한 맥락을 설명할 수 있습니다.
다른 취약점 객체의 필드를 반복해서는 안 됩니다.
특히, description은 location(영향을 받는 것)이나 solution(위험을 완화하는 방법)을 반복해서는 안 됩니다.
솔루션
solution 필드를 사용하여 사용자에게 식별된 취약점을 수정하거나 위험을 완화하는 방법을 안내할 수 있습니다. 최종 사용자는 이 필드와 상호작용하고, GitLab은 remediations 객체를 자동으로 처리합니다.
식별자
identifiers 배열은 감지된 취약점을 설명합니다. 식별자 객체의 type 및 value 필드는 두 개의 식별자가 동일한지 확인하기 위해 사용됩니다. 사용자 인터페이스는 객체의 name 및 url 필드를 사용하여 식별자를 표시합니다.
이미 GitLab 스캐너가 정의한 식별자를 사용하는 것이 좋습니다:
| 식별자 | 유형 | 예제 값 | 예제 이름 |
|---|---|---|---|
| CVE | cve |
CVE-2019-10086 | CVE-2019-10086 |
| CWE | cwe |
1026 | CWE-1026 |
| ELSA | elsa |
ELSA-2020-0085 | ELSA-2020-0085 |
| OSVD | osvdb |
OSVDB-113928 | OSVDB-113928 |
| OWASP | owasp |
A01:2021 | A01:2021 - Broken Access Control |
| RHSA | rhsa |
RHSA-2020:0111 | RHSA-2020:0111 |
| USN | usn |
USN-4234-1 | USN-4234-1 |
| GHSA | ghsa |
GHSA-38jh-8h67-m7mj | GHSA-38jh-8h67-m7mj |
| HACKERONE | hackerone |
698789 | HACKERONE-698789 |
위에 나열된 일반 식별자는 GitLab이 유지 관리하는 일부 분석기가 공유하는 공통 라이브러리에서 정의됩니다. 필요한 경우 새로운 일반 식별자를 기여할 수 있습니다. 분석기는 또한 공통 라이브러리에는 포함되지 않는 공급업체 또는 제품별 식별자를 생성할 수 있습니다.
identifiers 배열의 첫 번째 항목은 기본 식별자라고 하며, 이는 새로운 커밋이 리포지토리에 푸시될 때 취약점을 추적하는 데 사용됩니다.
모든 취약점이 CVE를 가지는 것은 아니며, CVE는 여러 번 식별될 수 있습니다. 결과적으로 CVE는 안정적인 식별자가 아니며 취약점을 추적할 때 그렇게 가정해서는 안 됩니다.
하나의 취약점에 대한 최대 식별자 수는 20으로 설정됩니다. 만약 취약점이 20개 이상의 식별자를 가지고 있다면, 시스템은 그 중 첫 20개만 저장합니다. 파이프라인 보안 탭의 취약점은 이 한계를 적용하지 않으며 보고서 아티팩트에 있는 모든 식별자를 표시합니다.
세부 정보
details 필드는 취약성 정보를 볼 때 표시되는 다양한 내용 요소를 지원하는 객체입니다. 다양한 데이터 요소의 예는 security-reports 리포지토리에서 볼 수 있습니다.
위치
location은 취약성이 감지된 위치를 나타냅니다.
위치의 형식은 스캔 유형에 따라 다릅니다.
GitLab은 내부적으로 location의 일부 속성을 추출하여 location fingerprint를 생성하는데, 이는 새로운 커밋이 리포지토리에 푸시될 때 취약성을 추踪하는 데 사용됩니다.
위치 핑거프린트를 생성하는 데 사용되는 속성도 스캔 유형에 따라 달라집니다.
의존성 스캐닝
의존성 스캐닝 취약성의 location은 dependency와 file로 구성됩니다.
dependency 객체는 영향을 받은 package와 의존성 version을 설명합니다.
package는 영향을 받은 라이브러리/모듈의 name을 포함합니다.
file은 영향을 받은 의존성을 선언하는 의존성 파일의 경로입니다.
예를 들어, npm 패키지 handlebars의 버전 4.0.11에 영향을 미치는 취약성의 location 객체는 다음과 같습니다:
{
"file": "client/package.json",
"dependency": {
"package": {
"name": "handlebars"
},
"version": "4.0.11"
}
}
이 영향을 받은 의존성은 client/package.json에 나열되어 있으며,
npm 또는 yarn에 의해 처리되는 의존성 파일입니다.
의존성 스캐닝 취약성의 위치 fingerprint는 file과 패키지 name을 결합하므로, 이 속성들은 필수입니다.
다른 모든 속성은 선택적입니다.
컨테이너 스캐닝
의존성 스캐닝과 유사하게,
컨테이너 스캐닝 취약성의 location에도 dependency와 file이 있습니다.
또한 operating_system 필드가 있습니다.
예를 들어, Debian 패키지 glib2.0의 버전 2.50.3-2+deb9u1에 영향을 미치는 취약성의 location 객체는 다음과 같습니다:
{
"dependency": {
"package": {
"name": "glib2.0"
},
},
"version": "2.50.3-2+deb9u1",
"operating_system": "debian:9",
"image": "registry.gitlab.com/example/app:latest"
}
영향을 받은 패키지는 Docker 이미지 registry.gitlab.com/example/app:latest를 스캔할 때 발견됩니다.
Docker 이미지는 debian:9(Debian Stretch)를 기반으로 합니다.
컨테이너 스캐닝 취약성의 위치 fingerprint는 operating_system과 패키지 name을 결합하므로, 이 속성들은 필수입니다.
image 역시 필수입니다.
다른 모든 속성은 선택적입니다.
SAST
SAST 취약성의 location은 영향을 받은 파일의 경로를 제공하는 file과 영향을 받은 줄 번호를 가진 start_line 필드가 있어야 합니다.
또한 end_line, class, 및 method를 가질 수 있습니다.
예를 들어, src/main/java/com/gitlab/example/App.java의 41번째 줄에서 발견된 보안 결함의 location 객체는 다음과 같습니다:
{
"file": "src/main/java/com/gitlab/example/App.java",
"start_line": 41,
"end_line": 41,
"class": "com.gitlab.security_products.tests.App",
"method": "generateSecretToken1"
}
SAST 취약성의 위치 fingerprint는 file, start_line, 및 end_line을 결합하므로, 이 속성들은 필수입니다.
다른 모든 속성은 선택적입니다.
취약점 추적 및 병합
사용자는 취약점에 대해 피드백을 제공할 수 있습니다:
- 그들은 프로젝트에 적용되지 않는 경우 취약점을 무시할 수 있습니다.
- 그들은 가능한 위협이 있는 경우 취약점에 대한 이슈를 생성할 수 있습니다.
GitLab은 사용자 피드백이 새로운 Git 커밋이 리포지토리에 푸시될 때 잃어버리지 않도록 취약점을 추적합니다.
취약점은 다음의 네 가지 속성의 SHA-1 해시로 생성되는 UUIDv5 다이제스트를 사용하여 추적됩니다:
현재 GitLab은 위치가 변경될 경우 취약점을 추적할 수 없습니다
새로운 Git 커밋이 푸시됨에 따라 이는 사용자 피드백이 손실되는 결과를 초래합니다.
예를 들어, 영향을 받은 파일의 이름이 변경되거나 영향받는 행이 아래로 이동하는 경우
SAST 취약점에 대한 사용자 피드백이 손실됩니다.
이는 이슈 #7586에서 다루어집니다.
또한 중복 제거 과정을 참조하세요.
심각도
severity 필드는 취약점이 소프트웨어에 얼마나 심각하게 영향을 미치는지를 설명합니다.
심각도는 보안 대시보드에서 취약점을 정렬하는 데 사용됩니다.
심각도는 Info에서 Critical까지 범위가 있지만, Unknown일 수도 있습니다.
유효한 값은: Unknown, Info, Low, Medium, High, 또는 Critical입니다.
Unknown 값은 실제 값을 결정할 수 있는 데이터가 없다는 것을 의미합니다.
따라서 이것은 high, medium, low일 수 있으며, 조사가 필요합니다.
수정 조치
보고서의 remediations 필드는 수정 조치 개체의 배열입니다.
각 수정 조치는 취약점을 해결하기 위해 적용할 수 있는 패치를 설명합니다.
다음은 수정 조치가 포함된 보고서의 예입니다.
{
"vulnerabilities": [
{
"category": "dependency_scanning",
"name": "정규 표현식 서비스 거부",
"id": "123e4567-e89b-12d3-a456-426655440000",
"solution": "새 버전으로 업그레이드합니다.",
"scanner": {
"id": "gemnasium",
"name": "Gemnasium"
},
"identifiers": [
{
"type": "gemnasium",
"name": "Gemnasium-642735a5-1425-428d-8d4e-3c854885a3c9",
"value": "642735a5-1425-428d-8d4e-3c854885a3c9"
}
]
}
],
"remediations": [
{
"fixes": [
{
"id": "123e4567-e89b-12d3-a456-426655440000"
}
],
"summary": "새로운 버전으로 업그레이드",
"diff": "ZGlmZiAtLWdpdCBhL3lhcm4ubG9jayBiL3lhcm4ubG9jawppbmRleCAwZWNjOTJmLi43ZmE0NTU0IDEwMDY0NAotLS0gYS95Y=="
}
]
}
요약
summary 필드는 취약점을 수정하는 방법에 대한 개요입니다. 이 필드는 필수입니다.
수정된 취약점
fixes 필드는 수정된 취약점을 참조하는 객체의 배열입니다. fixes[].id는 수정된 취약점의 고유 식별자를 포함합니다. 이 필드는 필수입니다.
차이
diff 필드는 Base64로 인코딩된 수정 코드 차이로, git apply와 호환됩니다. 이 필드는 필수입니다.
 도움말
도움말