Gitaly 및 Gitaly 클러스터
Gitaly는 Git 리포지토리에 대한 높은 수준의 RPC 액세스를 제공합니다.
GitLab에서 Git 데이터를 읽고 쓸 때 사용됩니다.
Gitaly는 모든 GitLab 설치에 존재하며 Git 리포지토리
저장 및 검색을 조정합니다. Gitaly는 다음과 같이 구성될 수 있습니다:
- 단일 인스턴스 Linux 패키지 설치에서 작동하는 백그라운드 서비스 (모든
GitLab이 한 대의 머신에 설치됨). - 확장성과 가용성 요구 사항에 따라 자체 인스턴스로 분리되고 전체 클러스터 구성으로
구성됨.
Gitaly는 클라이언트-서버 아키텍처를 구현합니다:
- Gitaly 서버는 Gitaly 자체를 실행하는 모든 노드입니다.
- Gitaly 클라이언트는 Gitaly 서버에 요청을 하는 프로세스를 실행하는 모든 노드입니다. Gitaly 클라이언트는 _Gitaly 소비자_라고도 하며 다음을 포함합니다:
Gitaly는 GitLab에 대한 Git 리포지토리 액세스만 관리합니다.
다른 유형의 GitLab 데이터는 Gitaly를 사용하여 액세스되지 않습니다.
GitLab은 구성된 저장소에 접근합니다
저장소 스토리지를 통해. 각 새로운 리포지토리는
구성된 가중치에 따라
하나의 저장소 스토리지에 저장됩니다. 각 저장소 스토리지는 다음 중 하나입니다:
-
저장 경로를 사용하여 리포지토리에 직접 액세스하는 Gitaly 저장소로,
각 리포지토리는 단일 Gitaly 노드에 저장됩니다. 모든 요청은 이 노드로 라우팅됩니다. -
Gitaly 클러스터에서 제공하는 가상 스토리지로,
각 리포지토리는 내결함성을 위해 여러 Gitaly 노드에 저장될 수 있습니다. Gitaly 클러스터에서:- 읽기 요청은 여러 Gitaly 노드 간에 분배되어 성능을 향상시킬 수 있습니다.
- 쓰기 요청은 리포지토리 복제본에 방송됩니다.
Gitaly 클러스터 배포 전
Gitaly 클러스터는 내결함성의 이점을 제공하지만,
설정 및 관리의 추가 복잡성이 따릅니다. Gitaly 클러스터를 배포하기 전에 다음을 검토하세요:
- 기존 알려진 문제.
- 스냅샷 제한 사항.
- Gitaly 클러스터가 귀하에게 최적의 설정인지 확인하기 위한
구성 가이드라인 및 저장소 스토리지 옵션.
아직 Gitaly 클러스터로 마이그레이션하지 않았다면 두 가지 옵션이 있습니다:
- 샤딩된 Gitaly 인스턴스.
- Gitaly 클러스터.
질문이 있는 경우 고객 성공 관리자 또는 고객 지원팀에 문의하세요.
알려진 문제
다음 표는 Gitaly Cluster 사용에 영향을 미치는 현재 알려진 문제를 요약합니다.
이 문제의 현재 상태에 대해서는 참조된 문제 및 에픽을 참조하세요.
| 문제 | 요약 | 회피 방법 |
|---|---|---|
| Gitaly Cluster + Geo - 실패한 동기화를 다시 시도하는 문제 | Gitaly Cluster가 Geo 보조 사이트에서 사용될 경우, 동기화에 실패한 리포지토리는 Geo가 다시 동기화하려 할 때 계속해서 실패할 수 있습니다. 이 상태에서 복구하려면 수동 단계를 실행하기 위해 지원의 도움이 필요합니다. | GitLab 15.0부터 15.2까지, Geo 주요 사이트에서 gitaly_praefect_generated_replica_paths 기능 플래그를 활성화하세요. GitLab 15.3에서는 기능 플래그가 기본적으로 활성화되어 있습니다. |
| 업그레이드 후 마이그레이션이 적용되지 않아 Praefect가 데이터베이스에 데이터를 삽입할 수 없음 | 데이터베이스가 완료된 마이그레이션으로 최신 상태로 유지되지 않으면 Praefect 노드는 표준 작업을 수행할 수 없습니다. | Praefect 데이터베이스가 모든 마이그레이션이 완료된 상태로 실행되고 있는지 확인하세요 (예: sudo -u git -- /opt/gitlab/embedded/bin/praefect -config /var/opt/gitlab/praefect/config.toml sql-migrate-status는 적용된 모든 마이그레이션 목록을 보여줍니다). 업그레이드 지원 요청을 고려하여 지원팀이 업그레이드 계획을 검토할 수 있도록 하세요. |
| 작동 중인 클러스터에서 스냅샷으로 Gitaly Cluster 노드 복원 | Gitaly Cluster가 일관된 상태로 실행되기 때문에, 뒤쳐진 단일 노드를 도입하면 클러스터가 노드 데이터와 다른 노드 데이터를 조정할 수 없습니다. | 백업 스냅샷에서 단일 Gitaly Cluster 노드를 복원하지 마세요. 백업에서 복원해야 하는 경우: 1. GitLab 종료. 2. 모든 Gitaly Cluster 노드를 동시에 스냅샷합니다. 3. Praefect 데이터베이스의 데이터베이스 덤프를 가져옵니다. |
| Kubernetes, Amazon ECS 또는 유사한 환경에서 실행 시 제한 사항 | Praefect (Gitaly Cluster)는 지원되지 않으며 Gitaly에는 알려진 제한 사항이 있습니다. 자세한 내용은 에픽 6127를 참조하세요. | 우리의 참조 아키텍처를 사용하세요. |
스냅샷 백업 및 복원 제한사항
Gitaly Cluster는 스냅샷 백업을 지원하지 않습니다. 스냅샷 백업은 Praefect 데이터베이스가 디스크 저장소와 동기화되지 않는 문제를 일으킬 수 있습니다. Praefect가 복원 중에 Gitaly 디스크 정보의 복제 메타데이터를 재구성하는 방식으로 인해 공식 백업 및 복원 Rake 작업을 사용하는 것이 좋습니다.
증분 백업 방법을 사용하여 Gitaly Cluster 백업 속도를 높일 수 있습니다.
두 방법 모두 사용할 수 없는 경우 고객 지원에 연락하여 복원 도움을 요청하세요.
Gitaly Cluster에서 문제나 제한 사항이 발생하는 경우 할 일
고객 지원에 연락하여 즉각적인 복원 또는 복구 도움을 받으세요.
디스크 요구 사항
Gitaly 및 Gitaly 클러스터는 효과적으로 작동하기 위해 빠른 로컬 스토리지가 필요합니다. 이들은 I/O 기반 프로세스이며, 따라서 모든 Gitaly 노드가 SSD(솔리드 스테이트 드라이브)를 사용하는 것을 강력하게 권장합니다.
이 SSD는 최소한 다음의 처리량을 가져야 합니다:
- 읽기 작업을 위한 초당 8,000 입력/출력 작업(I/O Operations Per Second, IOPS).
- 쓰기 작업을 위한 초당 2,000 IOPS.
이 IOPS 값은 초기 권장 사항이며, 환경의 작업 부하 규모에 따라 더 높거나 낮은 값으로 조정될 수 있습니다. 클라우드 제공업체에서 환경을 운영하는 경우, IOPS를 올바르게 구성하는 방법에 대한 문서를 참조하세요.
레포지토리 데이터의 경우, 성능 및 일관성 이유로 Gitaly 및 Gitaly 클러스터에 대해 로컬 스토리지만 지원됩니다.
NFS 또는 클라우드 기반 파일 시스템과 같은 대안은 지원되지 않습니다.
레포지토리 직접 접근
GitLab은 Git 클라이언트나 다른 도구로 디스크에 저장된 Gitaly 레포지토리 직접 접근을 권장하지 않습니다. Gitaly가 지속적으로 개선되고 변화하기 때문입니다. 이러한 개선은 당신의 가정을 무효화할 수 있으며, 성능 저하, 불안정성, 심지어 데이터 손실을 초래할 수 있습니다. 예를 들어:
- Gitaly에는
info/refs광고 캐시와 같은 최적화가 있으며, 이는 Gitaly가 공식 gRPC 인터페이스를 사용하여 레포지토리 접근을 제어하고 모니터링하는 데 의존합니다. - Gitaly 클러스터에는 gRPC 인터페이스 및 데이터베이스에 따라 레포지토리 상태를 결정하는 결함 허용 및 분산 읽기와 같은 최적화가 포함되어 있습니다.
경고: Git 레포지토리를 직접 접근하는 것은 본인의 위험 부담 하에 이루어지며 지원되지 않습니다.
Gitaly
다음은 GitLab이 Gitaly에 직접 접근하도록 설정한 모습입니다:

이 예제에서:
- 각 레포지토리는
storage-1,storage-2, 또는storage-3중 하나의 Gitaly 스토리지에 저장됩니다. - 각 스토리지는 Gitaly 노드에 의해 서비스됩니다.
- 세 개의 Gitaly 노드는 자신의 파일 시스템에 데이터를 저장합니다.
Gitaly 아키텍처
다음은 Gitaly 클라이언트-서버 아키텍처를 보여줍니다:
Gitaly 구성
Gitaly는 Linux 패키지 설치로 기본 구성되어 있으며, 이는 최대 20 RPS / 1,000 사용자에 적합한 구성입니다. 다음을 위해:
- 최대 40 RPS / 2,000 사용자를 위한 Linux 패키지 설치는 특정 Gitaly 구성 지침을 참조하세요.
- 자체 컴파일된 설치 또는 사용자 정의 Gitaly 설치는 Gitaly 구성을 참조하세요.
일일 Git 쓰기 작업을 수행하는 2,000명 이상의 활성 사용자를 위한 GitLab 설치는 Gitaly 클러스터를 사용하는 것이 가장 적합할 수 있습니다.
Gitaly CLI
gitaly git하위 명령어가 GitLab 17.4에서 도입되었습니다.
gitaly 명령은 Gitaly 관리자를 위한 추가 하위 명령어를 제공하는 명령줄 인터페이스입니다. 예를 들어, Gitaly CLI는 다음을 위해 사용됩니다:
- 리포지토리에 대한 사용자 정의 Git 훅 구성하기.
- Gitaly 구성 파일 유효성 검사.
- 내부 Gitaly API 접근 가능성 확인.
- 디스크上的 리포지토리에 대한 Git 명령 실행하기.
다른 하위 명령어에 대한 자세한 정보는 sudo -u git -- /opt/gitlab/embedded/bin/gitaly --help를 실행하세요.
리포지토리 백업
GitLab을 사용하지 않고 도구로 리포지토리를 백업하거나 동기화할 때에는 리포지토리 데이터를 복사하는 동안 쓰기 방지를 해야 합니다.
번들 URI
Gitaly와 함께 Git 번들 URI를 사용할 수 있습니다. 더 많은 정보는 번들 URI 문서를 참조하세요.
Gitaly 클러스터
Git 스토리는 GitLab의 Gitaly 서비스를 통해 제공되며, GitLab 운영에 필수적입니다. 사용자의 수, 리포지토리, 활동이 증가함에 따라 Gitaly의 적절한 스케일링이 중요합니다:
- 리소스 고갈이 Git, Gitaly 및 GitLab 애플리케이션 성능을 저하시켜 버리기 전에 사용 가능한 CPU 및 메모리 리소스를 늘리기.
- 스토리지 제한에 도달하기 전에 사용 가능한 스토리지 증가로 인해 쓰기 작업이 실패하지 않도록 하기.
- 단일 실패 지점을 제거하여 내결함성을 향상시키기. 서비스 저하가 프로덕션에 변경 사항을 배포할 수 없게 만들 경우 Git은 미션 크리티컬로 간주해야 합니다.
Gitaly는 클러스터 구성으로 실행할 수 있으며, 이를 통해:
- Gitaly 서비스를 스케일링합니다.
- 내결함성을 증가시킵니다.
이 구성에서 모든 Git 리포지토리는 클러스터의 여러 Gitaly 노드에 저장할 수 있습니다.
Gitaly 클러스터를 사용하면 내결함성이 증가합니다:
- 따뜻한 대기 Gitaly 노드에 쓰기 작업을 복제함으로써.
- Gitaly 노드 실패를 감지합니다.
- 사용 가능한 Gitaly 노드로 Git 요청을 자동으로 라우팅합니다.
다음은 Gitaly 클러스터가 제공하는 가상 스토리지 storage-1에 접근하기 위해 설정된 GitLab을 보여줍니다:
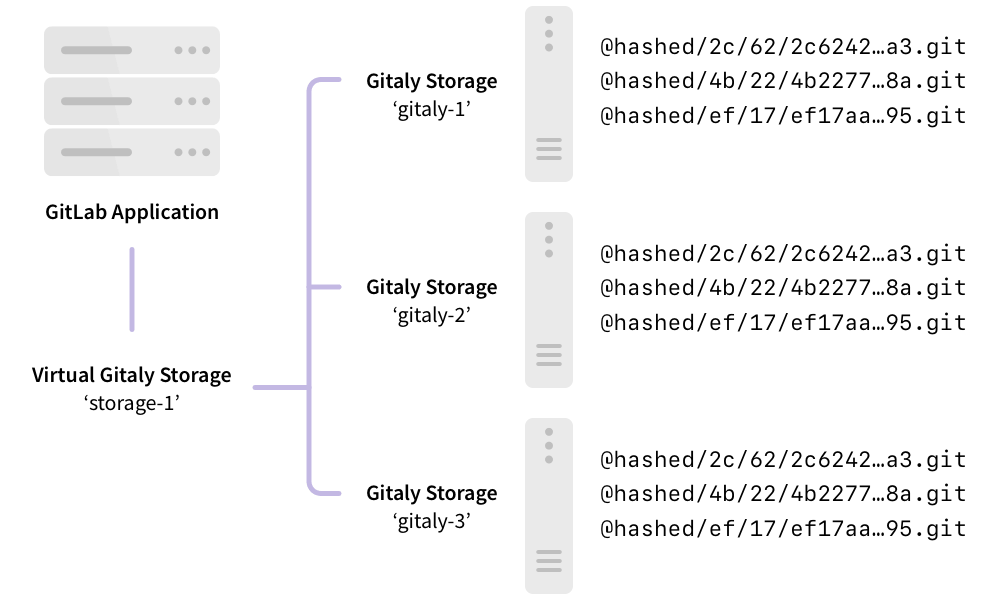
이 예에서:
- 리포지토리는
storage-1이라는 가상 스토리지에 저장됩니다. - 세 개의 Gitaly 노드가
storage-1접근을 제공합니다:gitaly-1,gitaly-2, 및gitaly-3. - 이 세 개의 Gitaly 노드는 세 개의 개별 해시 스토리지 위치에서 데이터를 공유합니다.
-
복제 계수는
3입니다. 각 리포지토리에 대한 세 개의 복사본이 유지됩니다.
단일 노드 실패를 가정한 Gitaly 클러스터의 가용성 목표는 다음과 같습니다:
-
복구 지점 목표 (RPO): 1분 미만.
쓰기는 비동기적으로 복제됩니다. 새로 승격된 주 노드에 복제되지 않은 모든 쓰기 작업은 손실됩니다.
강력한 일관성은 일부 상황에서 손실을 방지합니다.
-
복구 시간 목표 (RTO): 10초 미만.
장애는 매초 각 Praefect 노드에서 실행되는 건강 점검에 의해 감지됩니다. 장애 조치는 각 Praefect 노드에서 연속적으로 10번의 건강 점검 실패가 필요합니다.
RPO와 RTO에 대한 향상은 에픽 8903에서 제안되었습니다.
완전한 클러스터 실패가 발생하는 경우, 재해 복구 계획이 실행되어야 합니다. 이는 앞서 언급한 RPO와 RTO에 영향을 줄 수 있습니다.
Geo에 대한 비교
Gitaly Cluster와 Geo는 둘 다 중복성을 제공합니다. 그러나 중복성은 다음과 같습니다:
-
Gitaly Cluster는 데이터 저장을 위한 고장 허용성을 제공하며, 사용자에게는 보이지 않습니다. 사용자는 Gitaly Cluster가 사용될 때 인식하지 못합니다.
-
Geo는 전체 GitLab 인스턴스에 대해 복제 및 재난 복구를 제공합니다. 사용자는 복제를 위해 Geo를 사용할 때 인식합니다. Geo는 다양한 데이터 유형을 복제합니다, Git 데이터 포함하여.
다음 표는 Gitaly Cluster와 Geo 간의 주요 차이점을 요약합니다:
| 도구 | 노드 | 위치 | 지연 허용 수준 | 장애 조치 | 일관성 | 중복성 제공 대상 |
|---|---|---|---|---|---|---|
| Gitaly Cluster | 여러 개 | 단일 | 1초 미만, 이상적으로는 10밀리초 단위 | 자동 | 강력한 | Git 데이터 저장 |
| Geo | 여러 개 | 여러 개 | 1분까지 | 수동 | 최종적 | 전체 GitLab 인스턴스 |
자세한 정보는 다음을 참조하세요:
가상 스토리지
가상 스토리지는 GitLab에서 리포지토리 관리를 단순화하기 위해 단일 리포지토리 저장소를 가질 수 있게 합니다.
Gitaly Cluster로 가상 스토리지는 일반적으로 직접 Gitaly 저장소 구성으로 대체할 수 있습니다.
하지만 이는 여러 Gitaly 노드에 각 리포지토리를 저장하는 데 필요한 추가 저장 공간의 대가를 치르게 됩니다. Gitaly Cluster 가상 스토리지를 사용하는 이점은 다음과 같습니다:
-
각 Gitaly 노드가 모든 리포지토리의 복사본을 가지고 있어 고장 허용성이 향상됩니다.
-
읽기 부하가 Gitaly 노드에 분산되어 샤드 별 피크 부하에 대한 과잉 프로비저닝의 필요성이 줄어들어 리소스 활용도가 향상됩니다.
-
성능을 위한 수동 재조정이 필요하지 않습니다, 읽기 부하가 Gitaly 노드에 분산되어 있기 때문에.
-
모든 Gitaly 노드가 동일하기 때문에 관리가 간단합니다.
리포지토리 복제본 수는 복제 인자를 사용하여 구성할 수 있습니다.
모든 리포지토리에 대해 동일한 복제 인자를 갖는 것은 비경제적일 수 있습니다.
특히 큰 GitLab 인스턴스에 더 큰 유연성을 제공하기 위해 가변 복제 인자가 이 문제에서 추적됩니다.
표준 Gitaly 저장소와 마찬가지로, 가상 저장소는 분할될 수 있습니다.
저장소 레이아웃
경고:
저장소 레이아웃은 Gitaly Cluster의 내부 세부 사항이며, 릴리즈 간에 안정성을 유지한다고 보장할 수 없습니다.
여기에 있는 정보는 정보 제공을 위한 것이며 디버깅을 돕는 것입니다. 디스크에서 리포지토리를 직접 수정하는 것은 지원되지 않으며, 이는 오류를 초래하거나 변경 사항이 덮어쓰여질 수 있습니다.
Gitaly Cluster의 가상 저장소는 단일 저장소처럼 보이는 추상화를 제공하지만 실제로는 여러 물리적 저장소로 구성됩니다. Gitaly Cluster는 각 작업을 각 물리적 저장소에 복제해야 합니다. 작업은 일부 물리적 저장소에서는 성공할 수 있지만, 다른 저장소에서는 실패할 수 있습니다.
부분적으로 적용된 작업은 다른 작업에 문제를 일으키고 시스템을 복구할 수 없는 상태로 만들 수 있습니다. 이러한 유형의 문제를 피하기 위해 각 작업은 완전히 적용되거나 전혀 적용되지 않아야 합니다. 작업의 이 속성을 원자성이라고 합니다.
GitLab은 리포지토리 저장소의 저장소 레이아웃을 제어합니다. GitLab은 리포지토리 저장소에 리포지토리를 생성, 삭제 및 이동하도록 지시합니다. 이러한 작업은 여러 물리적 저장소에 적용될 때 원자성 문제를 일으킬 수 있습니다. 예를 들면:
-
GitLab이 한 리포지토리가 사용 불가능한 동안 해당 리포지토리를 삭제합니다.
-
GitLab이 나중에 해당 리포지토리를 다시 생성합니다.
이로 인해 삭제 당시 사용 불가능했던 오래된 리포지토리가 충돌을 일으키고 리포지토리의 재생성이 방지될 수 있습니다.
이러한 원자성 문제는 과거에 다음과 같은 여러 문제를 일으켰습니다:
-
Gitaly Cluster와 함께 보조 사이트로의 Geo 동기화.
-
백업 복원.
-
리포지토리 저장소 간의 리포지토리 이동.
Gitaly Cluster는 리포지토리를 디스크에 원자성 문제를 방지하는 특별한 레이아웃으로 저장하여 이러한 작업에 대한 원자성을 제공합니다.
클라이언트 생성 복제 경로
저장소는 Gitaly 클라이언트에 의해 결정된 상대 경로에 저장소에 저장됩니다. 이러한 경로는 @cluster 접두어로 시작하지 않음으로써 식별할 수 있습니다. 상대 경로는 해시된 저장소 스키마를 따릅니다.
프레펙트 생성 복제 경로
- GitLab 15.0에서
gitaly_praefect_generated_replica_paths라는 플래그와 함께 소개됨. 기본적으로 비활성화되어 있습니다.- GitLab 15.2에서 GitLab.com에서 활성화됨.
- GitLab 15.3에서 셀프 관리에서 활성화됨.
- GitLab 15.6에서 일반적으로 사용 가능. 기능 플래그
gitaly_praefect_generated_replica_paths가 제거됨.
Gitaly 클러스터가 저장소를 생성하면, 저장소에 _저장소 ID_라고 불리는 고유하고 영구적인 ID를 할당합니다. 저장소 ID는 Gitaly 클러스터 내에서만 사용되며 GitLab 내의 다른 ID와는 관련이 없습니다. 저장소가 Gitaly 클러스터에서 제거된 후 다시 이동되면, 저장소에 새로운 저장소 ID가 할당되며 Gitaly 클러스터의 관점에서 다른 저장소입니다. 저장소 ID의 순서는 항상 증가하지만, 순서에는 간격이 있을 수 있습니다.
저장소 ID는 클러스터의 각 저장소에 대해 _복제 경로_라고 하는 고유한 저장소 경로를 유도하는 데 사용됩니다. 저장소의 복제본은 모두 같은 복제 경로에 저장됩니다. 복제 경로는 _상대 경로_와는 다릅니다:
- 상대 경로는 Gitaly 클라이언트가 그들만의 고유한 가상 저장소와 함께 저장소를 식별하는 데 사용하는 이름입니다.
- 복제 경로는 물리적 저장소 내의 실제 물리적 경로입니다.
프레펙트는 클라이언트 요청을 처리할 때 가상 (가상 저장소, 상대 경로) 식별자를 물리적 저장소 (저장소, replica_path) 식별자로 변환합니다.
복제 경로 형식은 다음과 같습니다:
- 객체 풀은
@cluster/pools/<xx>/<xx>/<repository ID>입니다. 객체 풀은 다른 저장소와 다른 디렉토리에 저장됩니다. 그들은 Gitaly에 의해 식별 가능해야 하며, 관리 작업의 일환으로 그들이 잘리는 것을 피해야 합니다. 객체 풀의 잘림은 연결된 저장소에서 데이터 손실을 초래할 수 있습니다. - 다른 저장소는
@cluster/repositories/<xx>/<xx>/<repository ID>입니다.
예를 들어, @cluster/repositories/6f/96/54771입니다.
복제 경로의 마지막 구성 요소인 54771은 저장소 ID입니다. 이는 디스크에서 저장소를 식별하는 데 사용될 수 있습니다.
<xx>/<xx>는 저장소 ID의 문자열 표현의 SHA256 해시의 처음 네 개의 16진수 숫자입니다. 이러한 숫자는 저장소를 서브 디렉토리로 고르게 분산시키기 위해 사용되며, 일부 파일 시스템에서 문제를 일으킬 수 있는 과도하게 큰 디렉토리를 피하는 데 도움을 줍니다. 이 경우, 54771은 6f960ab01689464e768366d3315b3d3b2c28f38761a58a70110554eb04d582f7로 해싱되므로 처음 네 개의 숫자는 6f와 96입니다.
디스크에서 리포지토리 식별
praefect metadata 서브 명령어를 사용하여:
-
메타데이터 저장소에서 리포지토리의 가상 스토리지와 상대 경로를 검색합니다. 해시된 스토리지 경로를 얻은 후, Rails 콘솔을 사용하여 프로젝트 경로를 검색할 수 있습니다.
-
리포지토리가 클러스터에 저장된 위치를 다음을 통해 찾습니다:
- 가상 스토리지와 상대 경로.
- 리포지토리 ID.
디스크의 리포지토리에는 Git 구성 파일에 프로젝트 경로도 포함되어 있습니다. 구성 파일은 리포지토리의 메타데이터가 삭제된 경우에도 프로젝트 경로를 결정하는 데 사용할 수 있습니다. 해시된 스토리지 문서의 지침을 따르세요.
작업의 원자성
Gitaly Cluster는 리포지토리 생성, 삭제 및 이동 작업의 원자성을 보장하기 위해 PostgreSQL 메타데이터 저장소와 저장 레이아웃을 사용합니다. 디스크 작업은 여러 저장소에 원자적으로 적용될 수 없습니다. 그러나 PostgreSQL은 메타데이터 작업의 원자성을 보장합니다. Gitaly Cluster는 실패하는 작업이 항상 메타데이터를 일관성 있게 남기도록 작업을 모델링합니다. 디스크에는 성공적인 작업 후에도 오래된 상태가 남아 있을 수 있습니다. 이 상황은 예상되며 남은 상태는 향후 작업에 간섭하지 않지만 정리 작업이 수행될 때까지 불필요하게 디스크 공간을 사용할 수 있습니다.
저장소에서 남은 리포지토리를 정리하는 백그라운드 크롤러에 대한 작업이 진행 중입니다.
리포지토리 생성
리포지토리를 생성할 때, Praefect는:
-
PostgreSQL에서 리포지토리 ID를 예약하며, 이는 원자적이며 두 개의 생성이 동일한 ID를 받지 않습니다.
-
리포지토리 ID에서 파생된 복제 경로의 Gitaly 저장소에 복제본을 생성합니다.
-
리포지토리가 디스크에서 성공적으로 생성된 후 메타데이터 레코드를 생성합니다.
두 개의 동시 작업이 동일한 리포지토리를 생성하더라도, 각기 다른 디렉토리에 저장되어 충돌하지 않습니다. 먼저 완료된 작업이 메타데이터 레코드를 생성하고 다른 작업은 “이미 존재함” 오류와 함께 실패합니다. 실패한 생성 작업은 저장소에 남은 리포지토리를 남깁니다. 저장소에서 남은 리포지토리를 정리하는 백그라운드 크롤러에 대한 작업이 진행 중입니다.
리포지토리 ID는 PostgreSQL의 repositories_repository_id_seq에서 생성됩니다. 위의 예에서 실패한 작업은 리포지토리를 성공적으로 생성하지 않고 하나의 리포지토리 ID를 가져갔습니다. 실패한 리포지토리 생성은 리포지토리 ID에 공백이 발생하는 원인이 됩니다.
리포지토리 삭제
리포지토리는 메타데이터 레코드를 제거하여 삭제됩니다. 메타데이터 레코드가 삭제되는 즉시 리포지토리는 논리적으로 존재하지 않게 됩니다. PostgreSQL은 제거의 원자성을 보장하며, 동시 삭제는 “찾을 수 없음” 오류로 실패합니다. 메타데이터 레코드를 성공적으로 삭제한 후, Praefect는 저장소에서 복제본을 제거하려고 시도합니다. 이 작업이 실패하면 저장소에 남은 상태가 남아 있을 수 있습니다. 남은 상태는 결국 정리됩니다.
리포지토리 이동
Gitaly와 달리 Gitaly Cluster는 저장소에서 리포지토리를 이동하지 않고 메타데이터 저장소에서 리포지토리의 상대 경로를 업데이트하여 가상으로만 이동합니다.
구성 요소
Gitaly Cluster는 여러 구성 요소로 구성됩니다:
-
로드 밸런서: 요청을 분산하고 Praefect 노드에 대한 내결함성 액세스를 제공합니다.
-
Praefect 노드: 클러스터를 관리하고 요청을 Gitaly 노드로 라우팅합니다.
-
클러스터 메타데이터를 지속적으로 저장하기 위한 PostgreSQL 데이터베이스 및 PgBouncer: Praefect의 데이터베이스 연결 풀링에 권장됩니다.
-
리포지토리 저장소 및 Git 액세스를 제공하는 Gitaly 노드.
아키텍처
Praefect는 Gitaly의 라우터이자 트랜잭션 관리자로, Gitaly 클러스터를 실행하는 데 필요한 구성 요소입니다.
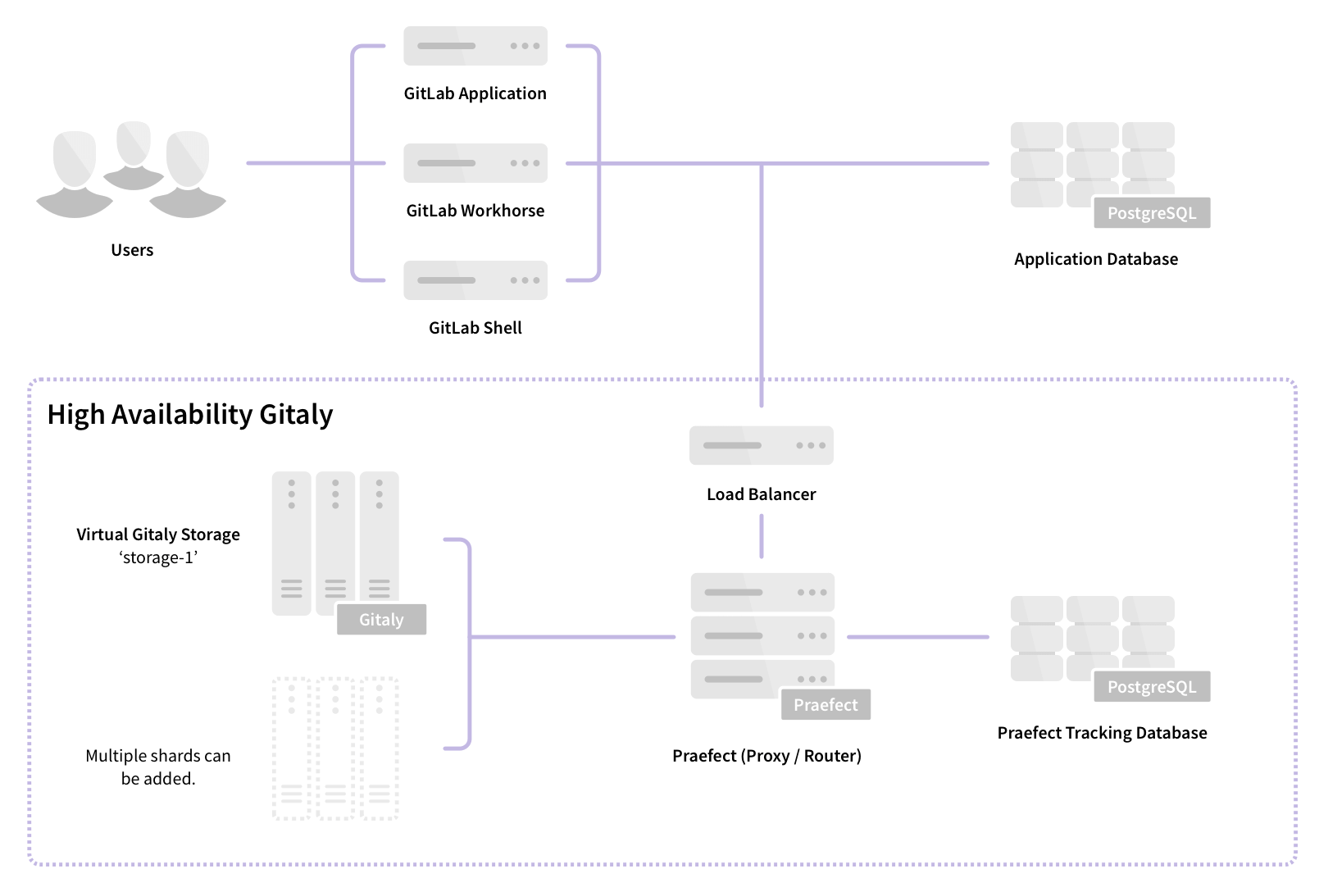
자세한 내용은 Gitaly 고가용성(HA) 설계를 참조하세요.
기능
Gitaly 클러스터는 다음과 같은 기능을 제공합니다:
- Gitaly 노드 간의 분산 읽기.
- 보조 복제본의 강력한 일관성.
- 증가된 중복성을 위한 복제 계수.
- 기본 Gitaly 노드에서 보조 Gitaly 노드로의 자동 장애 조치.
- 복제 큐가 비어있지 않을 경우 가능한 데이터 손실의 보고.
분산 읽기 수평 분포를 포함한 개선 사항은 Gitaly 클러스터 에픽을 팔로우하세요.
분산 읽기
Gitaly 클러스터는 가상 저장소에 대해 구성된 Gitaly 노드에서 읽기 작업의 분배를 지원합니다.
ACCESSOR 옵션이 지정된 모든 RPC는 최신 상태의 건강한 Gitaly 노드로 리다이렉트됩니다. 예를 들어, GetBlob.
_최신 상태_는 다음을 의미합니다:
- 이 Gitaly 노드에 대해 예약된 복제 작업이 없음.
- 마지막 복제 작업이 완료 상태임.
요청을 처리하기 위해 기본 노드를 선택하는 경우는 다음과 같습니다:
- 최신 상태의 노드가 존재하지 않는 경우.
- 노드 선택 중에 다른 오류가 발생하는 경우.
대규모로 변경이 많이 이루어지는 리포지토리(예: 다중 기가바이트 모노레포)를 사용하는 경우, 변경 사항이 Praefect가 보조 노드로 복제할 수 있는 속도보다 빠르게 들어오는 경우, 기본 노드가 대부분 또는 모든 요청을 처리할 수 있습니다. 이 경우 CI/CD 작업과 기타 리포지토리 트래픽은 기본 노드의 용량에 의해 병목 현상이 발생합니다.
읽기 분포 모니터링을 Prometheus를 사용하여 모니터링할 수 있습니다.
강력한 일관성
Gitaly 클러스터는 모든 건강한 최신 복제본에 변경 사항을 동기식으로 기록하여 강력한 일관성을 제공합니다. 트랜잭션 시 복제본이 구식이거나 건강하지 않은 경우, 기록된 데이터는 비동기적으로 복제됩니다.
강력한 일관성은 기본 복제 방법입니다. 일부 작업은 여전히 강력한 일관성 대신 복제 작업(최종 일관성)을 사용합니다. 자세한 내용은 강력한 일관성 에픽을 참조하세요.
강력한 일관성을 사용할 수 없는 경우, Gitaly 클러스터는 최종 일관성을 보장합니다. 이 경우, 기본 Gitaly 노드에 대한 기록이 발생한 후 모든 기록이 보조 Gitaly 노드로 복제됩니다.
강력한 일관성 모니터링에 대한 자세한 내용은 Gitaly 클러스터 Prometheus 메트릭 문서를 참조하세요.
복제 계수
복제 계수는 Gitaly 클러스터가 특정 리포지토리에 유지하는 복사본의 수입니다. 더 높은 복제 계수는 다음과 같습니다:
- 더 나은 중복성과 읽기 작업 부담의 분산을 제공합니다.
- 더 높은 저장 비용이 발생합니다.
기본적으로 Gitaly 클러스터는 모든 가상 저장소에 리포지토리를 복제합니다.
구성 정보는 복제 계수 구성을 참조하세요.
Gitaly 클러스터 구성
Gitaly 클러스터 구성에 대한 자세한 내용은 Gitaly 클러스터 구성을 참조하세요.
Gitaly 클러스터 업그레이드
Gitaly 클러스터를 업그레이드하려면 제로 다운타임 업그레이드 문서를 따르세요.
Gitaly 클러스터를 이전 버전으로 다운그레이드
Gitaly 클러스터를 이전 버전으로 롤백해야 하는 경우, 일부 Praefect 데이터베이스 마이그레이션을 되돌려야 할 수도 있습니다.
여러 Praefect 노드가 있다고 가정하고 Gitaly 클러스터를 다운그레이드하려면:
-
모든 Praefect 노드에서 Praefect 서비스를 중지합니다:
gitlab-ctl stop praefect -
Praefect 노드 중 하나에서 GitLab 패키지를 이전 버전으로 다운그레이드합니다.
-
다운그레이드된 노드에서 Praefect 마이그레이션 상태를 확인합니다:
sudo -u git -- /opt/gitlab/embedded/bin/praefect -config /var/opt/gitlab/praefect/config.toml sql-migrate-status -
APPLIED열에서unknown migration이 있는 마이그레이션 수를 세십시오. -
다운그레이드되지 않은 Praefect 노드에서 롤백의 드라이 실행을 수행하여 되돌릴 마이그레이션을 확인합니다.
<CT_UNKNOWN>은 다운그레이드된 노드에서 보고된 알려지지 않은 마이그레이션의 수입니다.sudo -u git -- /opt/gitlab/embedded/bin/praefect -config /var/opt/gitlab/praefect/config.toml sql-migrate <CT_UNKNOWN> -
결과가 올바르게 보이면,
-f옵션을 사용하여 마이그레이션을 되돌리기 위해 같은 명령을 실행합니다:sudo -u git -- /opt/gitlab/embedded/bin/praefect -config /var/opt/gitlab/praefect/config.toml sql-migrate -f <CT_UNKNOWN> -
나머지 Praefect 노드에서 GitLab 패키지를 다운그레이드하고 Praefect 서비스를 다시 시작합니다:
gitlab-ctl start praefect
Gitaly 클러스터로 마이그레이션
경고:
Gitaly 클러스터에는 일부 알려진 문제가 있습니다. 계속하기 전에 다음 정보를 검토하십시오.
Gitaly 클러스터로 마이그레이션하기 전에:
- Gitaly 클러스터 배포 전을 검토하세요.
- 개선 사항 및 버그 수정을 활용하기 위해 가능한 최신 버전의 GitLab로 업그레이드합니다.
Gitaly 클러스터로 마이그레이션하려면:
-
필요한 저장소를 생성합니다. 저장소 저장소 권장 사항을 참조하세요.
-
Gitaly 클러스터를 생성하고 구성합니다.
-
기존 Gitaly 인스턴스를 TCP를 사용하도록 구성합니다(아직 구성되지 않은 경우).
-
저장소 이동합니다. Gitaly 클러스터로 마이그레이션하기 위해 기존에 Gitaly 클러스터 외부에 저장된 저장소를 이동해야 합니다. 자동 마이그레이션은 없지만, 이동은 GitLab API를 사용하여 예약할 수 있습니다.
default 저장소 저장소를 사용하지 않더라도, 그것이 구성되어 있는지 확인해야 합니다. 이 제한 사항에 대해 자세히 읽어보세요.
Gitaly 클러스터에서 마이그레이션하기
Gitaly 클러스터의 제한 사항과 이점이 귀하의 환경에 적합하지 않다면, Gitaly 클러스터에서 분할된 Gitaly 인스턴스로 마이그레이션할 수 있습니다:
- 새로운 Gitaly 서버를 생성하고 구성합니다.
- 리포지토리 이동을 새로 생성된 스토리지로 이동합니다. 샤드별 또는 그룹별로 이동할 수 있으며, 이를 통해 여러 Gitaly 서버에 분산할 수 있는 기회를 제공합니다.
Gitaly 클러스터로의 전환
복잡성을 제거하기 위해, GitLab에서 직접적인 Git 접근을 제거해야 합니다. 그러나 일부 GitLab 설치가 NFS에 Git 리포지토리를 필요로 하는 한 이를 제거할 수 없습니다.
GitLab에서 직접적인 Git 접근을 제거하기 위한 우리의 노력에는 두 가지 측면이 있습니다:
- GitLab에서 실행되는 비효율적인 Gitaly 쿼리 수를 줄입니다.
- 내결함성이 있거나 수평으로 확장된 GitLab 인스턴스의 관리자가 NFS에서 마이그레이션하도록 설득합니다.
두 번째 측면이 유일한 실제 솔루션을 제공합니다. 이를 위해 우리는 Gitaly Cluster를 개발했습니다.
 도움말
도움말