배치로 테이블 반복하기
Rails는 in_batches라는 메서드를 제공하여
행을 배치로 반복할 수 있습니다. 예를 들어:
User.in_batches(of: 10) do |relation|
relation.update_all(updated_at: Time.now)
end
불행히도, 이 메서드는 효율성이 떨어지며 쿼리 및 메모리 사용 면에서 좋지 않게 구현되어 있습니다.
이 문제를 해결하기 위해, EachBatch 모듈을 모델에 포함시킨 후,
each_batch 클래스 메서드를 사용할 수 있습니다. 예를 들어:
class User < ActiveRecord::Base
include EachBatch
end
User.each_batch(of: 10) do |relation|
relation.update_all(updated_at: Time.now)
end
이것은 다음과 같은 쿼리를 생성합니다:
User Load (0.7ms) SELECT "users"."id" FROM "users" WHERE ("users"."id" >= 41654) ORDER BY "users"."id" ASC LIMIT 1 OFFSET 1000
(0.7ms) SELECT COUNT(*) FROM "users" WHERE ("users"."id" >= 41654) AND ("users"."id" < 42687)
이 메서드의 API는 in_batches와 유사하지만, in_batches가 지원하는 모든 인수를 지원하지 않습니다.
특별한 필요가 없는 한 항상 each_batch를 사용해야 합니다.
비고유 열 반복하기
비고유 열(관계의 맥락에서)에서는 each_batch 메서드를 사용하지 말아야 합니다.
무한 루프가 발생할 수 있습니다.
또한, 비고유 열을 반복할 때 일관성 없는 배치 크기가 성능 문제를 일으킬 수 있습니다.
속성을 반복할 때 최대 배치 크기를 적용하더라도
결과 배치가 이를 초과하지 않을 것에 대한 보장이 없습니다.
다음 스니펫은 id가 1과 10,000 사이인 사용자를 위한
Ci::Build 항목을 선택하려고 할 때 발생하는 상황을 보여줍니다.
데이터베이스는 1,215,178개의 일치하는 행을 반환합니다.
[ gstg ] production> Ci::Build.where(user_id: (1..10_000)).size
=> 1215178
이는 생성된 관계가 다음 쿼리로 변환되기 때문입니다:
[ gstg ] production> puts Ci::Build.where(user_id: (1..10_000)).to_sql
SELECT "ci_builds".* FROM "ci_builds" WHERE "ci_builds"."type" = 'Ci::Build' AND "ci_builds"."user_id" BETWEEN 1 AND 10000
=> nil
비고유 열을 범위로 필터링하는 And 쿼리인
WHERE "ci_builds"."user_id" BETWEEN ? AND ?는
범위 크기가 특정 한계(10,000 - 이전 예제라면)로 제한되더라도
반환된 데이터 세트의 크기를 보장하지 않습니다.
속성의 가능한 값 n을 가져올 때, 이들을 포함하는 레코드 수가
n보다 적다는 것을 확신할 수 없습니다.
distinct_each_batch와 느슨한 인덱스 스캔
비고유 열을 반복해야 하는 경우,
distinct_each_batch 헬퍼 메서드를 사용하세요.
이 헬퍼는 데이터베이스 인덱스 내에서 중복 값을 건너뛰기 위해
느슨한 인덱스 스캔 기법(skip-index scan)을 사용합니다.
예시: Issue 모델에서 고유한 author_id 반복하기
Issue.distinct_each_batch(column: :author_id, of: 1000) do |relation|
users = User.where(id: relation.select(:author_id)).to_a
end
이 기술은 데이터 분포와 관계없이 배치 간 안정적인 성능을 제공합니다.
relation 객체는 주어진 column만 사용할 수 있는 ActiveRecord 스코프를 반환합니다.
다른 열은 로드되지 않습니다.
기본 데이터베이스 쿼리는 재귀 CTE를 사용하여 추가 오버헤드를 발생시킵니다.
따라서 표준 each_batch 반복에서 사용되는 배치 크기보다
더 작은 배치 크기를 사용할 것을 권장합니다.
열 정의
EachBatch는 기본적으로 모델의 기본 키를 사용하여 반복합니다. 대부분의 경우 작동하지만, 몇 가지 경우에는 다른 열을 사용하여 반복하고 싶을 수 있습니다.
Project.distinct.each_batch(column: :creator_id, of: 10) do |relation|
puts User.where(id: relation.select(:creator_id)).map(&:id)
end
위 쿼리는 프로젝트 생성자를 반복하며 중복 없이 출력합니다.
참고:
열이 고유하지 않은 경우(고유 인덱스 정의가 없는 경우), 관계에서 distinct 메서드를 호출하는 것이 필요합니다. distinct 없이 고유하지 않은 열을 사용하는 경우, 다음의 문제에서 설명한 바와 같이 each_batch가 무한 루프에 빠질 수 있습니다.
데이터 마이그레이션에서의 EachBatch
대량의 데이터를 처리할 때 선호하는 방법은 EachBatch를 사용하는 것입니다.
데이터 마이그레이션의 특별한 경우는 실제 데이터 수정이 백그라운드 작업에서 실행되는 배치 백그라운드 마이그레이션입니다. 데이터 범위(슬라이스)를 결정하고 백그라운드 작업을 예약하는 마이그레이션 코드는 each_batch를 사용합니다.
each_batch의 효율적인 사용
EachBatch는 대규모 테이블을 반복하는 데 도움이 됩니다. EachBatch가 모든 반복 관련 성능 문제를 마법처럼 해결하는 것은 아니며, 일부 시나리오에서는 전혀 도움이 되지 않을 수 있다는 점을 강조하는 것이 중요합니다. 데이터베이스 관점에서, 올바르게 구성된 데이터베이스 인덱스가 EachBatch의 성능을 높이는 데 필요합니다.
예제 1: 간단한 반복
users 테이블을 반복하여 User 레코드를 표준 출력으로 출력하고 싶다고 가정해 보겠습니다. users 테이블은 수백만 개의 레코드를 포함하고 있으므로, 사용자를 가져오기 위해 단일 쿼리를 실행하는 것은 아마도 시간 초과가 발생할 것입니다.
이 테이블은 몇 가지 행을 포함하는 단순화된 users 테이블의 버전입니다. 예제를 조금 더 현실적으로 만들기 위해 id 열에 몇 개의 작은 간격이 있습니다(몇 개의 레코드가 이미 삭제되었습니다). id 필드에 인덱스가 하나 존재합니다:
ID |
sign_in_count |
created_at |
|---|---|---|
| 1 | 1 | 2020-01-01 |
| 2 | 4 | 2020-01-01 |
| 9 | 1 | 2020-01-03 |
| 300 | 5 | 2020-01-03 |
| 301 | 9 | 2020-01-03 |
| 302 | 8 | 2020-01-03 |
| 303 | 2 | 2020-01-03 |
| 350 | 1 | 2020-01-03 |
| 351 | 3 | 2020-01-04 |
| 352 | 0 | 2020-01-05 |
| 353 | 9 | 2020-01-11 |
| 354 | 3 | 2020-01-12 |
모든 사용자를 메모리로 로드하는 것(피해야 할 방법):
users = User.all
users.each { |user| puts user.inspect }
each_batch를 사용합니다:
# 주의: 이 예제에서는 배치 크기로 5를 선택했습니다. 기본값은 1_000입니다.
User.each_batch(of: 5) do |relation|
relation.each { |user| puts user.inspect }
end
each_batch 작동 방식
첫 번째 단계로, 다음 데이터베이스 쿼리를 실행하여 테이블에서 가장 낮은 id(시작 id)를 찾습니다:
SELECT "users"."id" FROM "users" ORDER BY "users"."id" ASC LIMIT 1
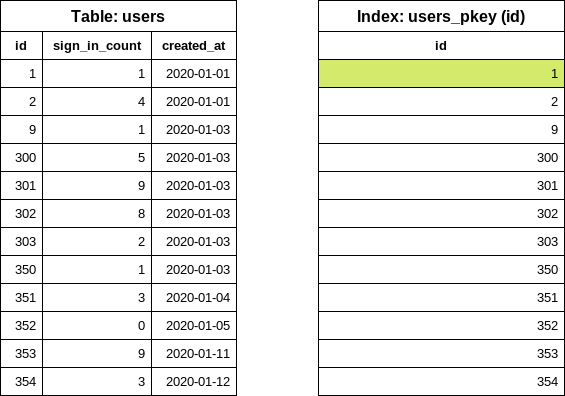
쿼리가 인덱스에서만 데이터를 읽는다는 점에 주목하세요(INDEX ONLY SCAN), 테이블은 접근하지 않습니다. 데이터베이스 인덱스는 정렬되어 있으므로 첫 번째 항목을 가져오는 것은 매우 저렴한 작업입니다.
다음 단계는 배치 크기 구성에 따라 다음 id(끝 id)를 찾는 것입니다. 이 예에서는 배치 크기로 5를 사용했습니다. EachBatch는 “변경된” id 값을 얻기 위해 OFFSET 절을 사용합니다.
SELECT "users"."id" FROM "users" WHERE "users"."id" >= 1 ORDER BY "users"."id" ASC LIMIT 1 OFFSET 5
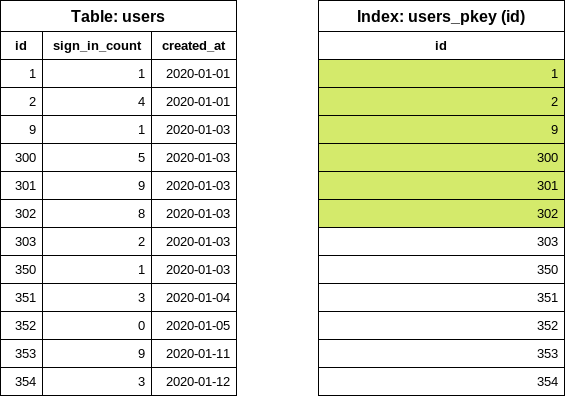
다시 한 번, 쿼리는 인덱스에서만 조회합니다. OFFSET 5는 여섯 번째 id 값을 가져옵니다. 이 쿼리는 테이블 크기나 반복 횟수에 관계없이 인덱스에서 최대 여섯 항목을 읽습니다.
이 시점에서 첫 번째 배치의 id 범위를 알고 있습니다. 이제 relation 블록을 위한 쿼리를 구성할 시간입니다.
SELECT "users".* FROM "users" WHERE "users"."id" >= 1 AND "users"."id" < 302
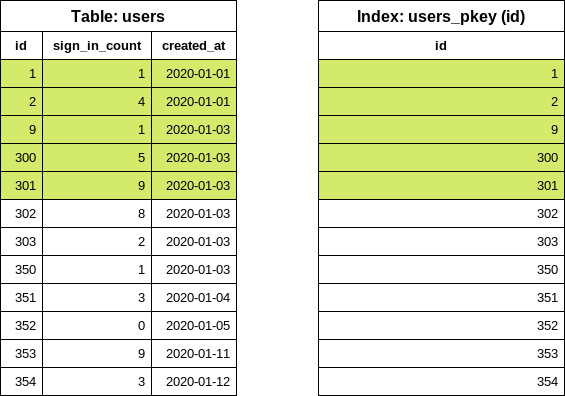
< 기호를 주목하세요. 이전에 인덱스에서 여섯 항목이 읽혔고, 이 쿼리에서는 마지막 값이 “제외”됩니다. 쿼리는 인덱스를 참조하여 디스크에서 다섯 개의 user 행의 위치를 찾고 테이블에서 행을 읽습니다. 반환된 배열은 Ruby에서 처리됩니다.
첫 번째 반복이 완료되었습니다. 다음 반복에서는 이전 반복에서 재사용된 마지막 id 값을 사용하여 다음 끝 id 값을 찾습니다.
SELECT "users"."id" FROM "users" WHERE "users"."id" >= 302 ORDER BY "users"."id" ASC LIMIT 1 OFFSET 5
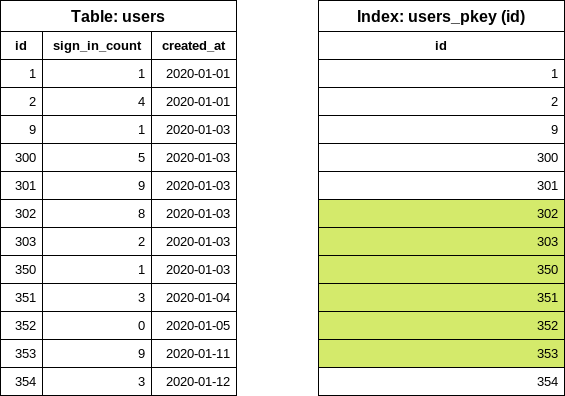
이제 두 번째 반복을 위한 users 쿼리를 쉽게 구성할 수 있습니다.
SELECT "users".* FROM "users" WHERE "users"."id" >= 302 AND "users"."id" < 353
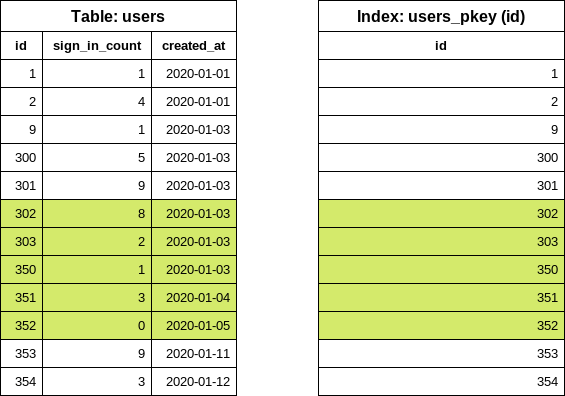
예제 2: 필터를 사용한 반복
이전 예제를 기반으로, 로그인 수가 0인 사용자를 출력하고자 합니다. 우리는 sign_in_count 열에서 로그인 수를 추적하므로 다음과 같이 코드를 작성합니다:
users = User.where(sign_in_count: 0)
users.each_batch(of: 5) do |relation|
relation.each { |user| puts user.inspect }
end
each_batch는 시작 id 값에 대해 다음 SQL 쿼리를 생성합니다:
SELECT "users"."id" FROM "users" WHERE "users"."sign_in_count" = 0 ORDER BY "users"."id" ASC LIMIT 1
id 열만 선택하고 id로 정렬하면 데이터베이스는 id(기본 키 인덱스) 열의 인덱스를 사용하도록 강제되지만, sign_in_count 열에 대한 추가 조건도 있습니다. 이 열은 인덱스의 일부가 아니므로, 데이터베이스는 실제 테이블을 조회하여 첫 번째 일치하는 행을 찾아야 합니다.

참고:
스캔된 행의 수는 테이블의 데이터 분포에 따라 다릅니다.
- 최상의 경우: 첫 번째 사용자가 로그인하지 않았습니다. 데이터베이스는 단 하나의 행만 읽습니다.
- 최악의 경우: 모든 사용자가 최소 한 번은 로그인했습니다. 데이터베이스는 모든 행을 읽습니다.
이 특정 예에서, 데이터베이스는 첫 번째 id 값을 결정하기 위해 10개의 행을 읽어야 했습니다(우리의 배치 크기 설정과 관계없이). “실제” 애플리케이션에서 필터링이 문제를 일으킬지 여부를 예측하기는 어렵습니다. GitLab의 경우, 프로덕션 복제본에서 데이터를 검증하는 것이 좋은 시작이지만, GitLab.com의 데이터 분포가 자체 관리 인스턴스와 다를 수 있다는 점을 유의해야 합니다.
each_batch를 통한 필터링 개선
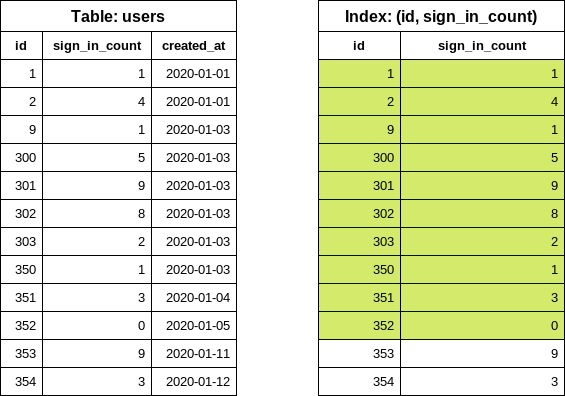
특수 조건 인덱스
CREATE INDEX index_on_users_never_logged_in ON users (id) WHERE sign_in_count = 0
우리의 테이블과 새로 생성된 인덱스는 다음과 같습니다:

이 인덱스 정의는 id 및 sign_in_count 열에 대한 조건을 포함하므로 each_batch 쿼리를 매우 효과적으로 만듭니다 (단순 반복 예와 유사합니다).
사용자가 로그인을 한 적이 없는 경우는 드물기 때문에, 우리는 작은 인덱스 크기를 예상합니다. 인덱스 정의에 id만 포함하는 것도 인덱스 크기를 작게 유지하는 데 도움을 줍니다.
열에 대한 인덱스
이후에 우리는 테이블을 반복하면서 다양한 sign_in_count 값을 필터링하고 싶을 수 있습니다. 그런 경우, 이전에 제안된 조건 인덱스를 사용할 수 없습니다. 왜냐하면 WHERE 조건이 새로운 필터(sign_in_count > 10)와 일치하지 않기 때문입니다.
이 문제를 해결하기 위해 두 가지 옵션이 있습니다:
- 새 쿼리를 포함할 조건 인덱스를 새로 생성합니다.
- 인덱스를 더 일반화된 구성으로 교체합니다.
참고: 같은 테이블과 같은 열에 여러 개의 인덱스를 갖는 것은 데이터 작성 시 성능 병목을 초래할 수 있습니다.
다음 인덱스를 고려해보겠습니다 (피해야 함):
CREATE INDEX index_on_users_never_logged_in ON users (id, sign_in_count)
인덱스 정의는 id 열로 시작하는데, 이는 데이터 선택성 관점에서 인덱스를 매우 비효율적으로 만듭니다.
SELECT "users"."id" FROM "users" WHERE "users"."sign_in_count" = 0 ORDER BY "users"."id" ASC LIMIT 1
위 쿼리를 실행하면 INDEX ONLY SCAN이 발생합니다. 그러나 쿼리는 여전히 인덱스에서 알 수 없는 수의 항목을 순회하고, sign_in_count가 0인 첫 번째 항목을 찾아야 합니다.
인덱스 정의에서 열을 바꾸면 쿼리를 크게 개선할 수 있습니다 (선호).
CREATE INDEX index_on_users_never_logged_in ON users (sign_in_count, id)
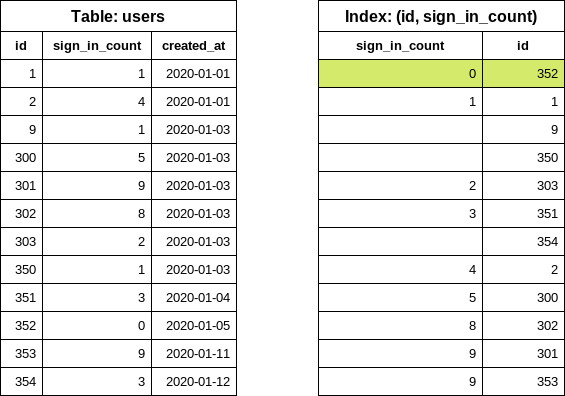
다음 인덱스 정의는 each_batch와 잘 작동하지 않습니다 (피해야 함).
CREATE INDEX index_on_users_never_logged_in ON users (sign_in_count)
each_batch가 id 열을 기반으로 범위 쿼리를 생성하므로, 이 인덱스를 효율적으로 사용할 수 없습니다. DB는 테이블에서 행을 읽거나 기본 키 인덱스를 읽는 비트맵 검색을 사용합니다.
“느린” 반복
느린 반복은 좋은 인덱스 구성을 사용하여 테이블을 반복하고 반환된 관계에 필터링을 적용하는 것을 의미합니다.
User.each_batch(of: 5) do |relation|
relation.where(sign_in_count: 0).each { |user| puts user inspect }
end
이 반복은 기본 키 인덱스(id 열)를 사용하므로 문장 타임아웃으로부터 안전합니다. 필터(sign_in_count: 0)는 id가 이미 제약을 받는 relation에 적용됩니다. 행의 수는 제한됩니다.
느린 반복은 일반적으로 완료하는 데 더 많은 시간이 걸립니다. 반복 수가 더 높고, 하나의 반복에서 배치 크기보다 적은 레코드를 반환할 수 있습니다. 반복이 0개의 레코드를 반환할 수도 있습니다. 이는 최적의 해결책은 아니지만, 어떤 경우(특히 큰 테이블을 다룰 때)에는 유일한 실행 가능한 옵션입니다.
서브쿼리 사용하기
each_batch 쿼리에서 서브쿼리를 사용하는 것은 대부분의 경우 잘 작동하지 않습니다. 다음 예를 고려해 보세요:
projects = Project.where(creator_id: Issue.where(confidential: true).select(:author_id))
projects.each_batch do |relation|
# do something
end
이 반복은 projects 테이블의 id 열을 사용합니다. 배치는 서브쿼리에 영향을 미치지 않습니다. 이는 각 반복마다 데이터베이스에서 서브쿼리가 실행됨을 의미합니다. 이로 인해 쿼리에 일정한 “부하”가 추가되어 종종 쿼리 타임아웃이 발생합니다. 우리는 비밀 이슈가 몇 개인지 모르며, 실행 시간과 접근되는 데이터베이스 행 수는 issues 테이블의 데이터 분포에 따라 달라집니다.
참고: 서브쿼리는 서브쿼리가 소수의 행을 반환할 때만 작동합니다.
서브쿼리 개선하기
서브쿼리를 처리할 때 느린 반복 접근 방식이 작동할 수 있습니다: creator_id에 대한 필터가 생성된 relation 객체의 일부가 될 수 있습니다.
projects = Project.all
projects.each_batch do |relation|
relation.where(creator_id: Issue.where(confidential: true).select(:author_id))
end
issues 테이블 자체에 대한 쿼리가 성능이 충분하지 않다면, 중첩 루프를 구성할 수 있습니다. 가능하면 이를 피하는 것이 좋습니다.
projects = Project.all
projects.each_batch do |relation|
issues = Issue.where(confidential: true)
issues.each_batch do |issues_relation|
relation.where(creator_id: issues_relation.select(:author_id))
end
end
issues 테이블에 projects보다 더 많은 행이 있다는 것을 알고 있다면, issues 테이블의 쿼리를 먼저 배치하는 것이 좋습니다.
JOIN 및 EXISTS 사용하기
JOINS를 사용할 때:
- 테이블 간의 1:1 또는 1:N 관계가 있을 때, 결합된 레코드가 (거의) 항상 존재하는 것을 알고 있는 경우입니다. 이는 “확장형” 테이블에 잘 작동합니다:
-
projects-project_settings -
users-user_details -
users-user_statuses
-
- 이 경우
LEFT JOIN이 잘 작동합니다. 결합된 테이블에 대한 조건은 생성된 관계로 전달되어야 하며, 데이터 분포로 인해 반복이 영향을 받지 않도록 해야 합니다.
예시:
User.each_batch do |relation|
relation
.joins("LEFT JOIN personal_access_tokens on personal_access_tokens.user_id = users.id")
.where("personal_access_tokens.name = 'name'")
end
EXISTS 쿼리는 each_batch 쿼리의 내부 relation에만 추가되어야 합니다:
User.each_batch do |relation|
relation.where("EXISTS (SELECT 1 FROM ...")
end
관계 객체에 대한 복잡한 쿼리
relation 객체에 여러 추가 조건이 있을 때, 실행 계획이 “불안정해”질 수 있습니다.
예시:
Issue.each_batch do |relation|
relation
.joins(:metrics)
.joins(:merge_requests_closing_issues)
.where("id IN (SELECT ...)")
.where(confidential: true)
end
여기서 우리는 relation 쿼리가 사용자 레코드의 BATCH_SIZE를 읽고 제공된 쿼리에 따라 결과를 필터링할 것이라고 기대합니다. 플래너는 confidential 열에 대한 인덱스를 사용하여 비트맵 인덱스 조회를 사용하는 것이 쿼리를 실행하는 더 좋은 방법이라고 결정할 수 있습니다. 이는 예상보다 많은 행이 읽히게 하고 쿼리가 타임아웃될 수 있습니다.
문제: 우리는 관계가 최대 BATCH_SIZE의 레코드를 반환하고 있다는 것을 확신하지만, 플래너는 이를 알지 못합니다.
공통 테이블 표현식(CTE) 트릭을 사용하여 범위 쿼리가 먼저 실행되도록 강제합니다:
Issue.each_batch(of: 1000) do |relation|
cte = Gitlab::SQL::CTE.new(:batched_relation, relation.limit(1000))
scope = cte
.apply_to(Issue.all)
.joins(:metrics)
.joins(:merge_requests_closing_issues)
.where("id IN (SELECT ...)")
.where(confidential: true)
puts scope.to_a
end
레코드 카운팅
데이터가 많은 테이블의 경우, 쿼리를 통해 레코드를 카운팅하면 시간 초과가 발생할 수 있습니다. EachBatch 모듈은 레코드를 반복적으로 카운팅할 수 있는 대체 방법을 제공합니다. each_batch를 사용할 때 단점은 수집된 관계 객체에 대해 추가 카운트 쿼리가 실행된다는 것입니다.
each_batch_count 메소드는 추가 카운트 쿼리의 필요성을 없애는 더 효율적인 접근 방식입니다. 이 메소드를 호출하면 반복 프로세스를 필요에 따라 일시 중지하고 다시 시작할 수 있습니다. 이 기능은 Sidekiq 작업 내에서 카운팅 작업을 수행할 때와 같이 다섯 분 후에 오류 예산 위반이 발생하는 상황에서 특히 유용합니다.
예를 들어, EachBatch를 사용하여 레코드를 카운팅하는 것은 다음과 같이 추가 카운트 쿼리를 호출하는 것을 포함합니다:
count = 0
Issue.each_batch do |relation|
count += relation.count
end
puts count
반면 each_batch_count 메소드는 추가 카운트 쿼리를 호출하지 않고(카운팅이 반복 쿼리의 일부임) 더 효율적으로 카운팅 프로세스를 수행할 수 있게 해줍니다:
count, _last_value = Issue.each_batch_count # 마지막 값은 무시할 수 있습니다
또한, each_batch_count 메소드는 카운팅 프로세스를 언제든지 일시 중지하고 다시 시작할 수 있게 해줍니다. 이 기능은 다음 코드 조각에서 보여집니다:
stop_at = Time.current + 3.minutes
count, last_value = Issue.each_batch_count do
stop_at.past? # 카운팅을 중단할 조건
end
# 나중에 카운팅을 계속합니다
stop_at = Time.current + 3.minutes
count, last_value = Issue.each_batch_count(last_count: count, last_value: last_value) do
stop_at.past?
end
EachBatch vs BatchCount
Service Ping의 새로운 카운터를 추가할 때, 레코드를 카운팅하는 선호 방법은 Gitlab::Database::BatchCount 클래스를 사용하는 것입니다. BatchCount에 구현된 반복 로직은 EachBatch와 유사한 성능 특성을 가지고 있습니다. 위에서 언급한 BatchCount를 개선하기 위한 대부분의 팁과 제안은 BatchCount에도 적용됩니다.
키셋 페이지네이션으로 반복하기
EachBatch로 반복하는 것이 작동하지 않는 몇 가지 특수한 경우가 있습니다. EachBatch는 하나의 고유한 열(보통 기본 키)을 요구하므로, 타임스탬프 열과 복합 기본 키가 있는 테이블에서는 반복이 불가능합니다.
EachBatch가 작동하지 않는 경우, 테이블이나 행 범위를 반복하기 위해 키셋 페이지네이션을 사용할 수 있습니다. 스케일링 및 성능 특성은 EachBatch와 매우 유사합니다.
예시:
- 특정 순서(타임스탬프 열)로 테이블을 반복하며 정렬할 때, 고유 값이 없는 열에 대해 타이브레이커 사용
- 복합 기본 키가 있는 테이블에서 반복하기
생성 날짜별로 프로젝트의 문제 반복하기
키셋 페이지네이션을 사용하여 특정 순서(created_at DESC)로 데이터베이스의 모든 열을 반복할 수 있습니다. created_at에 대해 동일한 값을 가진 레코드의 일관된 순서를 보장하기 위해, 고유 값을 가진 타이브레이커 열을 사용하세요(예: id).
issues 테이블에 다음과 같은 인덱스가 있다고 가정합니다:
idx_issues_on_project_id_and_created_at_and_id" btree (project_id, created_at, id)
추가 처리를 위한 레코드 가져오기
다음 스니펫은 지정된 순서(created_at, id)에 따라 프로젝트 내의 문제 레코드를 반복합니다:
scope = Issue.where(project_id: 278964).order(:created_at, :id) # id는 타이브레이커입니다
iterator = Gitlab::Pagination::Keyset::Iterator.new(scope: scope)
iterator.each_batch(of: 100) do |records|
puts records.map(&:id)
end
쿼리에 추가 필터를 추가할 수 있습니다. 이 예제는 지난 30일에 생성된 문제 ID만 나열합니다:
scope = Issue.where(project_id: 278964).where('created_at > ?', 30.days.ago).order(:created_at, :id) # id는 타이브레이커입니다
iterator = Gitlab::Pagination::Keyset::Iterator.new(scope: scope)
iterator.each_batch(of: 100) do |records|
puts records.map(&:id)
end
일괄 업데이트 레코드
복잡한 ActiveRecord 쿼리에 대해 .update_all 메소드는 잘 작동하지 않으며, 잘못된 UPDATE 문을 생성합니다.
레코드를 일괄적으로 업데이트하려면 원시 SQL을 사용할 수 있습니다:
scope = Issue.where(project_id: 278964).order(:created_at, :id) # id는 동점자로 사용됨
iterator = Gitlab::Pagination::Keyset::Iterator.new(scope: scope)
iterator.each_batch(of: 100) do |records|
ApplicationRecord.connection.execute("UPDATE issues SET updated_at=NOW() WHERE issues.id in (#{records.dup.reselect(:id).to_sql})")
end
참고:
반복(iteration)을 안정적이고 예측 가능하게 유지하려면 ORDER BY 절에서 열을 업데이트하지 마세요.
merge_request_diff_commits 테이블 반복
merge_request_diff_commits 테이블은 복합 기본 키 (merge_request_diff_id, relative_order)를 사용하며, 이로 인해 EachBatch를 효율적으로 사용할 수 없습니다.
merge_request_diff_commits 테이블을 페이지네이션 하려면 다음 코드를 사용할 수 있습니다:
# 사용자 정의 정렬 객체 구성:
order = Gitlab::Pagination::Keyset::Order.build([
Gitlab::Pagination::Keyset::ColumnOrderDefinition.new(
attribute_name: 'merge_request_diff_id',
order_expression: MergeRequestDiffCommit.arel_table[:merge_request_diff_id].asc,
nullable: :not_nullable
),
Gitlab::Pagination::Keyset::ColumnOrderDefinition.new(
attribute_name: 'relative_order',
order_expression: MergeRequestDiffCommit.arel_table[:relative_order].asc,
nullable: :not_nullable
)
])
MergeRequestDiffCommit.include(FromUnion) # 키셋 페이지네이션이 UNION 쿼리를 생성합니다.
scope = MergeRequestDiffCommit.order(order)
iterator = Gitlab::Pagination::Keyset::Iterator.new(scope: scope)
iterator.each_batch(of: 100) do |records|
puts records.map { |record| [record.merge_request_diff_id, record.relative_order] }.inspect
end
정렬 객체 구성
키셋 페이지네이션은 간단한 ActiveRecord order 스코프와 잘 작동합니다
(첫 번째 예제).
그러나 특별한 경우에는 기본 키셋 페이지네이션 라이브러리를 위해 ORDER BY 절의 열을 설명해야 합니다 (두 번째 예제).
ORDER BY 구성을 키셋 페이지네이션 라이브러리가 자동으로 결정할 수 없는 경우 오류가 발생합니다.
코드 주석은
Gitlab::Pagination::Keyset::Order
및 Gitlab::Pagination::Keyset::ColumnOrderDefinition
클래스가 ORDER BY 절을 구성하는 가능한 옵션을 개관합니다. 코드 예제는
키셋 페이지네이션 문서에서 찾을 수 있습니다.
 도움말
도움말