stage groups의 Observability
관측가능성은 시스템에 시각성을 제공하여 각 컴포넌트의 상태를 보고 이해하는 것으로, 성능 튜닝과 디버깅을 지원하기 위한 컨텍스트를 제공합니다. 규모에 맞게 SaaS 플랫폼을 운영하기 위해서는 풍부하고 상세한 관측가능성 플랫폼이 필요합니다.
stage groups에 정보를 제공하기 위해 기능 범주별로 메트릭을 집계하고 이 정보를 그룹에 맞게 조정된 대시보드에 표시합니다. 그룹이 작성한 기능에 대한 메트릭만 그들의 대시보드에서 볼 수 있습니다.
필터된 뷰로 그룹은 집계된 데이터를 확인할 때 놓칠 수 있는 버그 및 성능 하락을 발견할 수 있습니다.
대시보드에 대한 구체적인 정보는 다음을 참조하세요:
- 대시보드: 대시보드를 찾는 곳과 사용하는 방법에 대한 일반적인 개요.
- stage group 대시보드: stage group 대시보드의 사용 및 사용자 정의 방법.
- 오류 예산 상세: 시간 경과별 오류 예산 탐색 방법.
오류 예산
오류 예산은 GitLab.com을 모니터링하는 데 사용하는 서비스 수준 지표(SLI)와 동일하게 계산됩니다. 28일 가용성 수치는 그룹의 기능에 대해 계산되는 월별 가용성과 유사합니다.
오류 예산 사용에 대한 자세한 정보는 공학 오류 예산 핸드북 페이지를 참조하세요.
기본적으로 양 대시보드의 첫 번째 패널 행은 stage 그룹의 오류 예산을 보여줍니다. 이 행은 그룹이 소유한 기능이 전체 가용성에 어떻게 기여하는지 보여줍니다.
공식 예산은 28일 동안 집계됩니다. 이 예산은 stage group 대시보드에서 확인할 수 있습니다. 오류 예산 상세 대시보드에서는 범위를 사용자 정의할 수 있습니다.
우리는 정보를 두 가지 형식으로 표시합니다:
- 가용성: 이 수치는 GitLab.com 전체 가용성 목표인 99.95% 가동 시간과 비교할 수 있습니다.
- 예산 사용: 그룹이 소유한 기능이 충분히 작동하지 않은 지난 28일간의 시간입니다.
예산은 컴포넌트별 지표에 따라 계산됩니다. 각 컴포넌트는 두 가지 지표를 가질 수 있습니다:
-
Apdex: 적절하게 수행된 작업의 비율.
“적절하게 수행”되는 기준은 우리의 메트릭 카탈로그에 저장되어 있으며 해당 서비스에 따라 다릅니다. 예를 들어 API, Git 및 Web 서비스의 Puma(Rails) 컴포넌트에 대한 임계값은 5초입니다. 단,
rails_requestSLI를 선택하지 않은 경우라면 해당합니다.우리는 이 대상을 이 프로젝트에서 설정할 수 있게 했습니다. 요청 Apdex를 사용자 정의하려면 Rails request SLIs을 참조하세요. 이 새로운 Apdex 메트릭값은 가입할 때까지 오류 예산의 일부가 아닙니다.
Sidekiq 작업 실행의 경우 임계값은 작업 긴급도에 따라 달라집니다. 현재 고급 긴급 작업에 대한 임계값은 현재 10초이며, 다른 작업에 대한 임계값은 5분입니다.
일부 stage group에는 더 많은 서비스가 있을 수 있습니다. 그들에 대한 임계값 또한 메트릭 카탈로그에 있습니다.
-
오류율: 오류가 발생한 작업의 비율.
비율 계산은 다음과 같이 수행됩니다:
\frac {operations\_meeting\_apdex + (total\_operations - operations\_with\_errors)} {total\_apdex\_measurements + total\_operations}예산 사용 위치 확인
stage group 대시보드 및 오류 예산 상세 대시보드 모두, 오류 예산이 소비된 위치를 확인할 수 있는 패널을 표시합니다. stage group 대시보드는 항상 고정된 28일을 보여줍니다. 오류 예산 상세 대시보드는 시간 경과별 SLI로 드릴다운할 수 있습니다.
오류 예산 행 아래의 행은 기본적으로 축소됩니다. 펼치면 지난 28일 동안 가장 많은 문제 작업을 한 컴포넌트 및 위반 유형을 나타냅니다.

왼쪽의 첫 번째 패널은 컴포넌트별 오류 수를 보여주는 표입니다. 이 표에서 첫 번째 행을 파헤쳐보면 예산 사용에 가장 큰 영향을 미치게 됩니다.
일반적으로 예산을 가장 많이 차지하는 컴포넌트는 Sidekiq 또는 Puma입니다. 가운데의 패널은 다른 위반 유형의 의미와 로그를 자세히 파헤칠 방법을 설명합니다.
오른쪽 패널은 어떤 엔드포인트 또는 Sidekiq 작업이 오류를 발생시키는지 확인하는 Kibana로 연결하는 링크를 제공합니다.
이 패널과 로그를 사용하여 어떤 Rails 엔드포인트가 느린지 결정하는 방법에 대해 알아보려면 구매 그룹의 오류 예산 속성을 위한 비디오를 참조하세요.
표에서 볼 수 있는 다른 컴포넌트들은 서비스 수준 지표로부터 오며, 메트릭 카탈로그에서 정의됩니다.
이러한 유형의 오류의 경우 type 열에서 연결된 서비스 대시보드로 이동할 수 있습니다. 서비스 대시보드는 예산 사용에 영향을 미치는 특정 SLI를 위한 별도로 행을 포함하며, 로그에 대한 링크와 해당 컴포넌트의 설명을 제공합니다.
예를 들어, web-pages 서비스의 server 컴포넌트를 확인해보세요:

특정 기능에 맞게 추가 SLI를 추가하려면 Application SLI를 사용할 수 있습니다.
에러 버젯을 위한 키바나 대시보드
자세한 분석을 위해 전용 키바나 대시보드를 사용할 수 있습니다:
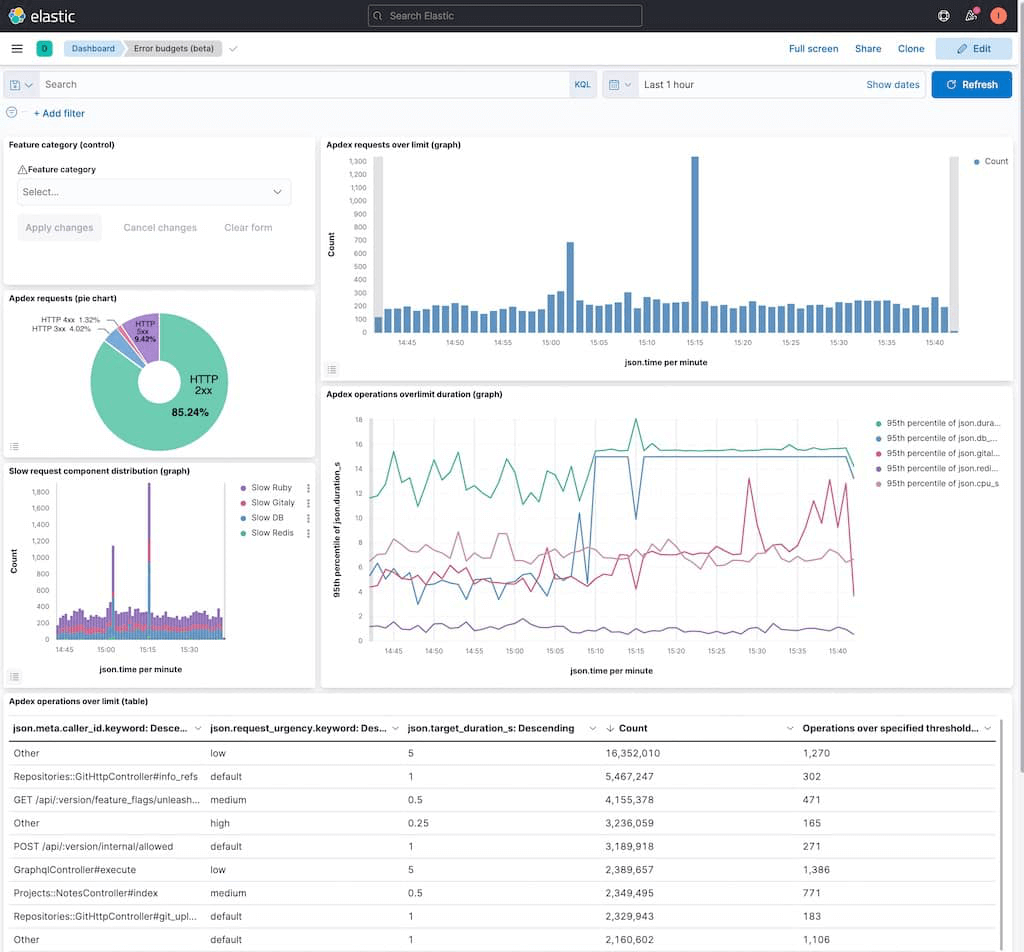
설명:
- Apdex 요청 초과 (그래프) - 목표 기간을 초과한 요청만 표시합니다.
- Apdex 작업 초과 기간 (그래프) - 지속 시간 컴포넌트 (데이터베이스, Redis, Gitaly, 및 Rails 앱)의 분포를 표시합니다.
-
Apdex 요청 (파이 차트) -
2xx,3xx,4xx, 및5xx요청의 백분율을 표시합니다. - 느린 요청 구성 구분 - Apdex 위반을 담당하는 컴포넌트를 강조 표시합니다.
- Apdex 작업 초과 제한 (테이블) - 각 엔드포인트에 대한 초과 작업 수를 표시합니다.
- Apdex 요청 초과 제한 - Apdex 위반을 담당하는 개별 요청 디렉터리을 표시합니다.
대시보드 사용
- 조사하려는 기능 범주를 선택합니다.
- 기능 카테고리 섹션으로 이동합니다. 기능 이름을 입력합니다.
- 변경 사항 적용을 선택합니다. 선택한 결과는 이 기능 카테고리와 관련된 요청만 포함합니다.
- 조사 기간을 선택합니다.
- 대시보드를 검토하고 실패의 유형에 주의를 기울입니다.
답변해야 할 질문:
- 실패 패턴은 급증과 같은가요? 아니면 지속적인가요?
- 실패는 특정 컴포넌트와 관련이 있나요? (데이터베이스, Redis, …)
- 실패는 특정 엔드포인트에 영향을 주나요? 아니면 시스템 전반에 영향을 주나요?
- 실패는 인프라 문제로 인한 것으로 보이나요?
 도움말
도움말