| Status | Authors | Coach | DRIs | Owning Stage | Created |
|---|---|---|---|---|---|
| ongoing |
@grzesiek
|
@ayufan
@grzesiek
|
@jreporter
@cheryl.li
| devops verify | 2022-05-31 |
- 어떤 문제를 해결하려고 하는가?
- CI/CD 데이터 분해, 파티셔닝, 시간 감쇠는 어떤 관련이 있나요?
- 왜 CI/CD 데이터를 파티션해야 하는가?
- CI/CD 데이터를 어떻게 파티션으로 나누길 원하십니까?
- 명시적 논리 파티션 ID를 사용하는 이유
- 파티셔닝된 테이블 변경
- 대형 파티션을 작은 파티션으로 분할
- 데이터베이스에 파티션 메타데이터 저장
- 파티셔닝을 사용하여 시간 감쇠 패턴 구현
- 반복
- 결론
- 누가
파이프라인 데이터 파티셔닝 설계
어떤 문제를 해결하려고 하는가?
CI/CD 데이터셋을 파티셔닝하려고 합니다. 왜냐하면 데이터베이스 테이블 중 일부가 매우 크기 때문에 CI/CD 데이터베이스 분해 후에도 단일 노드 읽기의 확장에 어려움을 겪을 수 있기 때문입니다.
CI/CD 데이터베이스 선언적 파티셔닝을 사용하여 가장 큰 데이터베이스 테이블 중 일부를 더 작은 테이블로 변환하여 데이터베이스 성능 하락의 위험을 줄이고자 합니다.
이 작업에 대한 자세한 내용은 상위 블루프린트에서 더 자세히 살펴볼 수 있습니다.
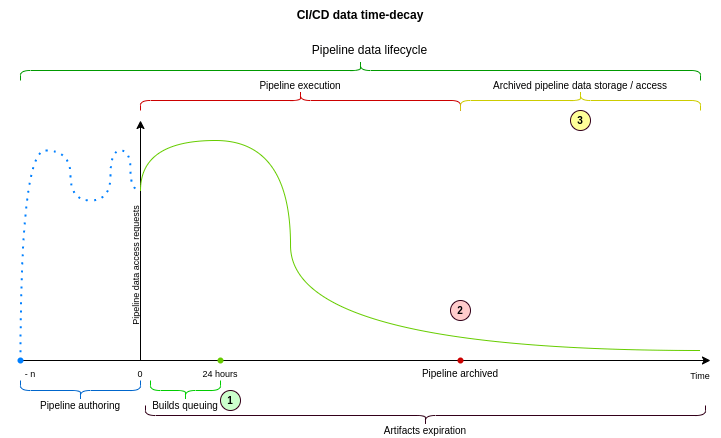
CI/CD 데이터 분해, 파티셔닝, 시간 감쇠는 어떤 관련이 있나요?
CI/CD 분해는 “주요” 데이터베이스 클러스터에서 CI/CD 데이터베이스 클러스터를 분리하여 다른 주 데이터베이스에서 쓰기를 수신할 수 있게 하는 것입니다. 주요 이점은 쓰기 및 데이터 저장용 용량을 두 배로 늘릴 수 있다는 것입니다. 새로운 데이터베이스 클러스터는 CI/CD 이외의 데이터베이스 테이블에 대한 읽기/쓰기를 제공할 필요가 없으므로 추가적인 읽기 용량을 제공합니다.
CI/CD 파티셔닝은 큰 CI/CD 데이터베이스 테이블을 더 작은 테이블로 분할하는 것입니다. 이렇게 하면 모든 CI/CD 데이터베이스 노드에서 읽기 용량이 개선됩니다. 왜냐하면 작은 테이블에서 데이터를 읽는 것이 수십 테라바이트의 대규모 테이블에서 읽는 것보다 훨씬 적은 비용이 들기 때문입니다. SQL 쿼리 수가 증가하더라도 CI/CD 데이터베이스 레플리카를 추가할 수 있지만, 효율적으로 단일 읽기를 수행하기 위해 파티셔닝이 필요합니다. 기타 측면의 성능도 개선될 것이며, PostgreSQL은 매우 큰 데이터베이스 테이블보다 여러 개의 작은 테이블을 유지하는 데 더 효율적일 것입니다.
CI/CD 시간 감쇠를 통해 파이프라인 데이터의 강력한 시간 감쇠 특성을 활용할 수 있습니다. 이는 다양한 방법으로 구현할 수 있지만, 파티셔닝을 사용하여 시간 감쇠를 구현하는 것이 특히 유익할 수 있습니다. 시간 감쇠를 구현할 때 일반적으로 데이터를 보관 및 해당 데이터가 관련이 없거나 필요하지 않을 때 데이터베이스에서 다른 위치로 이동합니다. 저희 데이터셋은 매우 크기 때문에(수십 테라바이트) 이러한 대량의 데이터를 이동하는 것은 어렵습니다. 파티셔닝을 사용하여 시간 감쇠를 구현하면 데이터베이스 테이블 중 하나에 있는 단일 레코드를 업데이트하여 전체 파티션(또는 여러 파티션 세트)을 보관할 수 있습니다. 이는 데이터베이스 수준에서 시간 감쇠 패턴을 구현하는 가장 비용 효율적인 방법 중 하나입니다.
왜 CI/CD 데이터를 파티션해야 하는가?
CI/CD 데이터를 파티션해야 하는 이유는 파이프라인, 빌드 및 아티팩트를 저장하는 데이터베이스 테이블이 너무 커져서입니다. ci_builds 데이터베이스 테이블 크기는 현재 약 2.5 TB이며, 인덱스 크기는 약 1.4 GB입니다. 이는 너무 크고 우리의 100 GB 최대 크기 원칙을 위반합니다. 또한, 이 숫자가 초과될 때 알림을 생성하고 싶습니다.
대규모 SQL 테이블은 새롭게 삭제된 튜플들이 autovacuum에 의해 정리되기 전에 색인 유지 시간을 증가시키는데, 이것은 작은 테이블이 필요하다는 점을 강조합니다. 우리는 거대한 테이블을 (재)색인할 때 얼마나 많은 증폭을 쌓이는지 메트릭할 것입니다. 이 분석을 토대로 (재)색인과 관련된 SLO(실제 삭제된 튜플/증폭)를 설정할 수 있을 것입니다.
지난 몇 달간 우리는 다양한 S1 및 S2 데이터베이스 관련 프로덕션 환경 사건들을 목격했습니다. 예를 들면 다음과 같습니다:
- S1: 2022-03-17
ci_builds테이블에 대한 쓰기 증가 - S1: 2021-11-22
ci_job_artifacts의 레플리카에서 과도한 버퍼 읽기 - S2: 2022-04-12 10분 이상 실행된 트랜잭션 감지
- S2: 2022-04-06 초과적인
ci_builds읽기로 인한 데이터베이스 경쟁 - S2: 2022-03-18
ci_builds에서 외래 키 제거 불가 - S2: 2022-10-10
queuing_queries_durationSLI의 SLO 위반
약 50개의 ci_* 접두사가 있는 데이터베이스 테이블이 있고, 그 중 일부는 파티셔닝이 필요할 것으로 생각됩니다.
이 데이터를 가져오기 위한 간단한 SQL 쿼리:
WITH tables AS (SELECT table_name FROM information_schema.tables WHERE table_name LIKE 'ci_%')
SELECT table_name,
pg_size_pretty(pg_total_relation_size(quote_ident(table_name))) AS total_size,
pg_size_pretty(pg_relation_size(quote_ident(table_name))) AS table_size,
pg_size_pretty(pg_indexes_size(quote_ident(table_name))) AS index_size,
pg_total_relation_size(quote_ident(table_name)) AS total_size_bytes
FROM tables ORDER BY total_size_bytes DESC;
2022년 3월 데이터:
| 테이블 명 | 총 크기 | 인덱스 크기 |
|---|---|---|
ci_builds
| 3.5 TB | 1 TB |
ci_builds_metadata
| 1.8 TB | 150 GB |
ci_job_artifacts
| 600 GB | 300 GB |
ci_pipelines
| 400 GB | 300 GB |
ci_stages
| 200 GB | 120 GB |
ci_pipeline_variables
| 100 GB | 20 GB |
| (…약 40개 더) |
위의 테이블에서 데이터가 많이 저장된 테이블이 명확합니다.
거의 50개의 CI/CD 관련 데이터베이스 테이블이 있지만, 우리는 처음에는 6개의 테이블에만 파티셔닝을 하려고 합니다. 우리는 점진적으로 가장 흥미로운 테이블을 파티셔닝함으로써 시작할 수 있지만, 필요한 경우 나머지 테이블도 파티셔닝해야 하는 전략을 가져야 합니다. 이 문서는 이 전략을 포착하고 가능한 많은 세부 사항을 설명하여 이 지식을 엔지니어링 팀 전체와 공유하려는 시도입니다.
CI/CD 데이터를 어떻게 파티션으로 나누길 원하십니까?
우리는 CI/CD 테이블을 반복적으로 파티션으로 나누고 싶습니다. 초기 6개의 테이블을 한꺼번에 파티션으로 나누는 것이 현실적으로 가능하지 않을 수 있기 때문에 반복적인 전략이 필요할 수 있습니다. 또한 나중에 나머지 데이터베이스 테이블을 파티션으로 나누어야 할 때를 위한 전략을 갖고 싶습니다.
대규모 데이터 이주를 피하는 것이 중요합니다. 우리는 가장 큰 CI/CD 테이블에 거의 6TB의 데이터를 다양한 열과 인덱스에 저장하고 있습니다. 이러한 양의 데이터를 마이그레이션하는 것은 어려울 수 있으며 프로덕션 환경에서 불안정성을 유발할 수 있습니다. 이러한 우려로, 우리는 기존 데이터베이스 테이블을 다운타임 없이 파티션 0으로 첨부하는 방법을 개발했습니다. 이 방법은 하나의 컨셉 증명 중 하나에서 시연되었습니다. 이를 통해 파티션 스키마를 다운타임 없이 생성할 수 있으며, 기존 ci_pipelines 테이블을 파티션 0으로 첨부하여 라우팅 테이블 p_ci_pipelines을 사용함으로써(ex. 라우팅 테이블 사용), 배타적 잠금을 줄입니다. 우리는 라우팅 테이블을 사용하려면 좋은 파티션 키를 찾아야 합니다.
우리의 계획은 논리적 파티션 ID를 사용하는 것입니다. 우리는 ci_pipelines 테이블부터 시작하여 partition_id 열을 만들고 DEFAULT 값을 100 또는 1000으로 설정하고 싶습니다. DEFAULT 값을 사용하면 각 행에 대해 이 값을 따로 채워 넣는 어려움을 피할 수 있습니다. 첫 번째 파티션을 첨부하기 전에 CHECK 제약 조건을 추가함으로써 PostgreSQL에게 이미 일관성을 보장했으며 이 테이블을 라우팅 테이블에 파티션으로 첨부할 때 배타적 테이블 잠금을 보유하는 동안 확인할 필요가 없음을 알립니다(파티션 스키마 정의). 우리는 p_ci_pipelines를 위해 새로운 파티션을 생성할 때마다 이 값을 증가시킬 것이며, 파티셔닝 전략은 LIST 파티셔닝입니다.
또한, 우리는 반복적으로 파티션으로 나누고자 하는 초기 6개의 데이터베이스 테이블에 partition_id 열을 생성할 것입니다. 새로운 파이프라인이 생성되면 partition_id가 할당되며, 빌드 및 아티팩트와 같은 관련 리소스는 모두 동일한 값으로 공유할 것입니다. 문제가 있는 6개의 테이블 모두에 partition_id 열을 추가하고 싶습니다. 이를 통해 이 데이터를 나중에 파티션으로 나누기로 결정할 때 데이터를 따로 채워 넣을 필요를 피할 수 있습니다.
CI/CD 데이터를 반복적으로 파티션으로 나누고 싶습니다. 우리의 계획은 빠르게 성장하는 테이블인 ci_builds_metadata 테이블부터 시작하는 것입니다. 이 테이블은 CI 데이터베이스에서 가장 빨리 성장하는 테이블이며 이 경향을 억제하고 싶습니다. 또한 이 테이블은 가장 간단한 액세스 패턴을 갖고 있습니다 - 빌드가 러너에 노출될 때 이 테이블에서 행을 읽고, 다른 액세스 패턴도 비교적 간단합니다. p_ci_builds_metadata를 시작으로 하면 조기에 구체적이고 양적인 결과를 달성할 수 있으며, 가장 큰 테이블을 파티션으로 나누는 새로운 패턴이 될 것입니다. 우리는 빌드 메타데이터를 LIST 파티셔닝 전략을 사용하여 파티션으로 나눌 것입니다.
p_ci_builds_metadata에 여러 파티션이 첨부되어 많은 partition_id가 있는 경우 다음에 파티션으로 나누고자 하는 다른 CI 테이블을 선택할 것입니다. 그 경우에는 ci_builds를 다음 파티션 후보로 선택할 수 있으며, p_ci_builds_metadata를 파티션으로 나누었을 때 이미 많은 물리적 파티션이 있고, 그러므로 많은 논리적 partition_id가 사용될 것입니다. 예를 들어, p_ci_builds_metadata를 파티션하고 나서 ci_builds.partition_id에 많은 다른 값들이 저장될 것입니다. 그런 경우 RANGE 파티셔닝을 사용하는 것이 더 쉬울 수 있습니다.
물리적 파티셔닝과 논리적 파티셔닝은 분리될 것이며, 각각의 데이터베이스 테이블에 대한 물리적 파티셔닝을 구현할 때 전략이 결정될 것입니다. RANGE 파티셔닝을 사용하는 것은 데이터베이스 테이블에서 LIST 파티셔닝을 사용하는 것과 유사하지만, partition_id 값을 연속성을 보장할 수 있기 때문에 RANGE 파티셔닝을 사용하는 것이 더 나은 전략일 수 있습니다.
멀티 프로젝트 파이프라인
부모-자식 파이프라인은 자식 파이프라인을 부모 파이프라인의 리소스로 간주하기 때문에 항상 같은 파티션의 일부가 될 것입니다. 이들은 프로젝트 파이프라인 디렉터리 페이지에서 개별적으로 볼 수 없습니다.
반면에, 멀티 프로젝트 파이프라인은 파이프라인 디렉터리 페이지에서 볼 수 있을 것입니다. 또한 trigger 토큰을 통해 생성되어 파이프라인 그래프에서 하류/상류 링크로 액세스할 수 있을 것입니다. 또한 작업 토큰을 사용하여 API를 통해 액세스할 수 있을 것입니다. 그런 파이프라인들은 다른 파이프라인에서 트리거 토큰을 사용하여 생성될 수 있지만, 이 경우에는 소스 파이프라인을 저장하지 않습니다.
ci_builds를 파티션으로 나눌 때는 ci_sources_pipelines 테이블에 대한 외래 키를 업데이트해야 합니다:
외래 키 제약조건:
"fk_be5624bf37" FOREIGN KEY (source_job_id) REFERENCES ci_builds(id) ON DELETE CASCADE
"fk_d4e29af7d7" FOREIGN KEY (source_pipeline_id) REFERENCES ci_pipelines(id) ON DELETE CASCADE
"fk_e1bad85861" FOREIGN KEY (pipeline_id) REFERENCES ci_pipelines(id) ON DELETE CASCADEci_sources_pipelines 레코드는 두 개의 ci_pipelines 행(부모 및 자식)을 참조합니다. 일반적인 전략은 테이블에 partition_id를 추가하는 것이었지만, 만약 여기에 이를 추가한다면 모든 멀티 프로젝트 파이프라인을 동일한 파티션으로 강제하게 될 것입니다.
이 테이블에 두 개의 partition_id 열을 추가해야합니다. partition_id 및 source_partition_id:
외래 키 제약조건:
"fk_be5624bf37" FOREIGN KEY (source_job_id, source_partition_id) REFERENCES ci_builds(id, source_partition_id) ON DELETE CASCADE
"fk_d4e29af7d7" FOREIGN KEY (source_pipeline_id, source_partition_id) REFERENCES ci_pipelines(id, source_partition_id) ON DELETE CASCADE
"fk_e1bad85861" FOREIGN KEY (pipeline_id, partition_id) REFERENCES ci_pipelines(id, partition_id) ON DELETE CASCADE이 해결책은 두 가지 결정이 가능한 중요한 결정과 가장 가깝습니다:
- 우리는 다른 파티션의 파이프라인을 참조할 수 있는 능력을 유지합니다.
- 나중에 멀티 프로젝트 파이프라인을 동일한 파티션으로 강제하길 원한다면 두 열이 동일한 값을 가지도록 하는 제약을 추가할 수 있을 것입니다.
명시적 논리 파티션 ID를 사용하는 이유
논리 partition_id를 사용하여 CI/CD 데이터를 파티션으로 나누는 것에는 여러 가지 이점이 있습니다. 기본 키로 파티션을 나눌 수도 있지만, 이로 인해 데이터의 구조화 및 파티션에 대한 이해에 필요한 복잡성과 인지 부하가 훨씬 더 커질 것입니다.
CI/CD 데이터는 계층적 데이터입니다. 단계는 파이프라인에 속하고, 빌드는 단계에 속하며, 아티팩트는 빌드에 속합니다(드물게 예외가 있음). 이러한 계층을 반영하는 파티셔닝 전략을 설계하여 기여자의 복잡성과, 결과적으로, 인지 부하를 줄일 수 있습니다. 파이프라인에 연관된 명시적 partition_id가 있는 경우 파티션 ID 번호를 해당 파이프라인과 연관된 모든 리소스를 검색할 때에도 연쇄적으로 사용할 수 있습니다. 파이프라인 12345의 partition_id가 102인 경우, 다른 라우팅 테이블에서 번호 102의 논리적 파티션에 항상 연관 리소스를 찾을 수 있으며 PostgreSQL은 각 테이블에 대해 레코드가 어느 파티션에 저장되어 있는지 알고 있을 것입니다.
파이프라인과 관련된 단일 및 점진적 최신 partition_id 번호를 사용하는 것은 이후에 더 많은 선택지를 제공할 수 있는데, 이는 기본 키 기반 파티셔닝보다 더 융통성을 가질 수 있다는 것입니다.
파티셔닝된 테이블 변경
파티셔닝된 테이블에 대해 ALTER TABLE 문을 여전히 실행하는 것은 가능할 것입니다. PostgreSQL이 부모 파티션이 있는 테이블에 ALTER TABLE 문을 실행하면 해당 테이블과 모든 하위 파티션에 동일한 잠금을 획들어 계속해서 동기화됩니다. 이는 비파티셔닝된 테이블에 ALTER TABLE을 실행하는 것과는 몇 가지 중요한 점에서 다릅니다.
- PostgreSQL은 더 많은 수의 테이블에 대해
ACCESS EXCLUSIVE잠금을 획들겠지만, 데이터의 양은 증가하지 않을 것입니다. 각 파티션은 부모 테이블과 유사하게 잠겨지고, 모든 것이 단일 트랜잭션 내에서 업데이트됩니다. - 잠금 기간은 관련된 파티션이 많을수록 증가할 것입니다. GitLab 데이터베이스에 실행된 모든
ALTER TABLE문은(조건 제약 확인을 제외하고) 수정된 테이블당 작은 일정 시간이 소요됩니다. PostgreSQL은 각 파티션을 순차적으로 수정해야 하므로 잠금의 실행 시간이 증가할 것입니다. 그 시간은 많은 파티션이 참여할 때까지 매우 작을 것입니다. - 수천 개의 파티션이
ALTER TABLE에 관여하는 경우, 운영 중인 잠금의 값이 작업 중에 차지해야 하는 모든 잠금을 지원할 수 있는지 확인해야 할 것입니다.
대형 파티션을 작은 파티션으로 분할
우리는 초기 partition_id 번호를 100 (또는 계산 및 추정에 따라 1000 등 더 높은 값)로 시작하고 싶습니다. 이미 존재하는 테이블도 이미 크기 때문에 1부터 시작하고 싶지 않으며, 작은 파티션으로 나누고 싶을 수도 있습니다. 100으로 시작하면 1, 20, 45의 partition_id에 대한 파티션을 만들고, 기존 레코드를 partition_id를 100에서 더 작은 번호로 업데이트하여 해당 파티션으로 레코드를 이동할 수 있을 것입니다.
PostgreSQL은 이러한 레코드들을 일관된 방식으로 이동하게 될 것이고, 이것은 트랜잭션으로 동시에 모든 파이프라인 리소스에 대해 이뤄질 때 가능할 것입니다. 우리가 대형 파티션을 작은 파티션으로 분할할 필요가 생기면(이것이 필요한지 아직 명확하지는 않음) 배경 마이그레이션을 사용하여 파티션 ID를 업데이트할 수 있을 것이고, PostgreSQL은 스스로 파티션 간에 행을 이동하는 데 똑똑하게 처리할 것입니다.
네이밍 규칙
파티셔닝된 테이블을 라우팅 테이블이라고 하며 p_ 접두사를 사용할 것이며, 쿼리 분석을 위한 자동화된 도구 구축에 도움이 될 것입니다.
테이블 파티션은 파티션이라고 하며 물리적 파티션 ID를 접미사로 사용할 수 있습니다. 예를 들면 ci_builds_101입니다. 기존 CI 테이블은 새로운 라우팅 테이블의 제로 파티션이 될 것입니다. 테이블의 선택한 파티셔닝 전략에 따라 하나의 물리적 파티션에 여러 논리적 파티션이 있을 수 있습니다.
첫 번째 파티션 연결 및 잠금 획들기
우리는 테이블을 파티션화할 때 PostgreSQL이 테이블과 외래 키를 통해 참조하는 모든 다른 테이블에 AccessExclusiveLock을 필요로 한다는 것을 알게 되었습니다. 이는 마이그레이션이 응용프로그램의 비즈니스 로직에서 다른 순서로 잠금을 획들 수 있어 데드락을 발생시킬 수 있습니다.
이 문제를 해결하기 위해 우리는 더 이상의 데드락 오류를 피하기 위한 우선 순위 잠금 전략을 도입했습니다. 이를 통해 잠금 순서를 정의하고 잠금을 획들 때까지 적극적으로 재시도할 수 있습니다. 이 과정은 최대 40분이 소요될 수 있습니다.
이 전략을 사용하여 우리는 00:00 UTC 이후에 낮은 트래픽 시간에 15번의 재시도 끝에 ci_builds 테이블에 잠금을 성공적으로 획들었습니다.
이 전략의 예시는 우리의 파티션 도구에서 확인할 수 있습니다.
파티션화 단계
데이터베이스 파티션 도구 문서에는 테이블을 파티션화하는 단계가 나와 있지만, 이러한 단계는 우리의 반복적인 전략에는 충분하지 않습니다. 데이터 집합이 계속해서 성장함에 따라 우리는 모든 테이블이 파티셔닝되기 전까지 기다리지 않고 파티셔닝 성능을 즉시 활용하고 싶습니다. 예를 들어, ci_builds_metadata 테이블을 파티셔닝한 후에는 새 파티션에 대해 데이터를 쓰고 읽고 싶을 것입니다. 이는 100이라는 기본값에서 101로 partition_id 값을 증가시킴으로써 가능할 것입니다. 이제 파이프라인 계층의 모든 새 리소스는 partition_id = 101로 저장될 것입니다. 다음으로 파티셔닝될 테이블에 대한 데이터베이스 도구 지침을 계속 따를 수 있지만, 몇 가지 추가 단계가 필요합니다:
- 기본값이
100인 FK 참조를 위한partition_id열 추가 - 애플리케이션 로직을 수정하여
partition_id값을 연쇄적으로 변경 -
최근 레코드에 대해
post deploy/background마이그레이션과 유사하게partition_id값을 수정UPDATE ci_pipeline_metadata SET partition_id = ci_pipelines.partition_id FROM ci_pipelines WHERE ci_pipelines.id = ci_pipeline_metadata.pipeline_id AND ci_pipelines.partition_id in (101, 102); - 외래 키 정의 변경
- …
데이터베이스에 파티션 메타데이터 저장
효율적인 메커니즘을 구축하여 새로운 파티션을 생성하고 시간 감쇠를 구현할 책임이 있으며 파티션 메타데이터 테이블인 ci_partitions를 도입하고자 합니다. 이 테이블에는 모든 논리적 파티션에 대한 메타데이터가 저장되며 각 파티션에는 많은 파이프라인이 포함될 수 있습니다. 논리적 파티션 당 파이프라인 ID 범위를 저장해야 할 수도 있습니다. 이를 사용하여 주어진 파이프라인 ID에 대한 partition_id 번호를 찾을 수 있을 뿐만 아니라 “활성” 또는 “보관”된 논리적 파티션이 어떤지에 대한 정보도 찾을 수 있습니다. 이는 데이터베이스 선언적 파티셔닝을 사용하여 시간 감쇠 패턴을 구현하는 데 도움이 될 것입니다.
이것을 통해 파티션된 리소스에 대한 통합 리소스 식별자를 사용할 수 있게 되며, 이 식별자는 파이프라인 ID를 가리키며, 이를 사용하여 리소스가 저장된 파티션을 효율적으로 조회할 수 있게 될 것입니다. 리소스가 URL에서 직접 참조될 수 있는 경우 UI나 API에서 중요할 수 있습니다. 우리는 파이프라인 123456, 빌드 23456에 대해 1e240-5ba0와 같은 ID를 사용할 수 있습니다. 대시 -를 사용하면 식별자가 마우스 더블 클릭으로 강조 표시되고 복사되는 것을 방지할 수 있습니다. 이 문제를 피하고 싶다면, 16진수 체계에 없는 문자로서의 기술적 표현에 있는 숫자 시스템에서의 g에서 z까지의 라틴 문자 중 어떤 글자든 사용할 수 있습니다. 예를 들어, x와 같이 할 수 있습니다. 이 경우 URI의 예는 1e240x5ba0와 같이 보일 것입니다. 파티션 리소스의 주 키를 업데이트하기로 결정하면 (현재는 큰 정수만 사용됨) 리밸런싱이 발생할 때 식별자를 변경하지 않도록 하는 시스템을 설계하는 것이 중요합니다.
ci_partitions 테이블에는 파티션 식별자, 그것이 유효한 파이프라인 ID 범위 및 파티션이 보관되었는지 여부에 대한 정보가 저장될 것입니다. 타임스탬프가 추가된 열도 유용할 수 있습니다.
파티셔닝을 사용하여 시간 감쇠 패턴 구현
우리는 선언적 파티셔닝을 사용하여 ci_partitions를 사용하여 시간 감쇠 패턴을 구현할 수 있습니다. PostgreSQL에게 어떤 논리적 파티션이 보관되었는지 알려줌으로써 이러한 파티션에서 읽기를 중단할 수 있습니다. 다음과 같은 SQL 쿼리를 사용하여 이 쿼리는 읽을 파티션의 수를 제한함으로써 “보관”된 파이프라인 데이터에 대한 액세스를 차단할 수 있게 할 것입니다.
SELECT * FROM ci_builds WHERE partition_id IN (
SELECT id FROM ci_partitions WHERE active = true
);
이 쿼리를 통해 우리는 읽게 될 파티션의 수를 제한할 수 있게되며 결과적으로 우리의 CI/CD 데이터의 데이터 보존 정책에 따라 “보관”된 파이프라인 데이터에 대한 액세스가 제한될 것입니다. 이상적으로 우리는 한 번에 두 개 이상의 파티션에서 읽지 않기를 원하기 때문에 자동 파티셔닝 메커니즘을 시간 감쇠 정책과 조율해야 할 것입니다. 여전히 ‘보관’된 데이터에 대한 새로운 액세스 패턴을 구현해야 하지만 이 방법으로 PostgreSQL에 저장하는 ‘보관’된 데이터의 비용이 크게 줄어들 것입니다.
파티션된 데이터 접근
GitLab의 대부분의 곳에서 ‘보관’되었는지 여부에 상관없이 파티션된 데이터에 액세스할 수 있을 것입니다. Merge Request 페이지에서 몇 년 전에 만들어진 Merge Request의 경우에도 항상 파이프라인 세부 정보를 표시할 것입니다. 이것은 ci_partitions가 파이프라인 ID와 해당 partition_id를 연관시키는 조회 테이블이기 때문입니다. 데이터베이스에 파이프라인 데이터가 저장된 파티션을 찾을 수 있을 것입니다.
우리는 파이프라인, 빌드, 아티팩트 등을 통한 검색에 액세스를 제약할 필요가 있을 것입니다. 모든 파티션을 통해 검색하는 것은 효율적이지 않기 때문에 ‘보관’된 파이프라인 데이터를 검색하는 더 나은 방법을 찾아야 할 것입니다. UI 및 API에서 ‘보관’된 데이터에 액세스하는 다른 액세스 패턴을 갖추는 것이 필요할 것입니다.
쿼리 분석기
우리는 파티셔닝된 테이블로 모든 작업이 계속되도록 수정해야 하는 쿼리를 감지하는 2개의 쿼리 분석기를 구현했습니다.
- 라우팅 테이블을 통과하지 않는 쿼리를 감지하는 분석기
-
WHERE절에서partition_id를 지정하지 않고 라우팅 테이블을 사용하는 쿼리를 감지하는 분석기
먼저 기존에 있는 깨진 쿼리를 감지하기 위해 첫 번째 분석기를 ‘test’ 환경에서 활성화했습니다. 또한 규모 확장에 대한 우려로 인해 ‘production’ 환경에서도 사용하지만 일부 트래픽(0.1%)에 대해서만 활성화했습니다.
두 번째 분석기는 향후 반복에서 활성화될 것입니다.
주 키
주 키는 테이블을 파티션하려면 파티션 키 열이 포함되어야 합니다.
우리는 먼저 (id, partition_id)를 포함하는 고유 인덱스를 생성합니다. 그런 다음 주 키 제약 조건을 삭제하고 새로 생성된 인덱스를 사용하여 새 주 키 제약 조건을 설정합니다.
ActiveRecord는 복합 주 키를 지원하지 않습니다 따라서 id 열을 주 키로 처리하도록 강제해야 합니다.
class Model < ApplicationRecord
self.primary_key = 'id'
end
응용 프로그램 계층은 이제 더 이상 데이터베이스 구조를 모르며, 기존의 ActiveRecord 쿼리는 여전히 데이터에 액세스하기 위해 id 열을 사용합니다. 이 접근 방식에는 id 값이 같은 다른 partition_id에 중복 모델이 생성될 수 있기 때문에 애플리케이션 코드를 구성할 때 이러한 위험이 있지만 이 위험을 완화하기 위해 모든 삽입이 데이터베이스 시퀀스를 사용하여 id를 할당하고, 액세스 패턴에 partition_id 값을 포함하도록 다시 작성해야 합니다. 삽입 중에 id를 매뉴얼으로 지정하는 것은 피해야 합니다.
외부 키
외부 키는 기본 키이거나 고유 제약 조건을 형성하는 열을 참조해야 합니다. 이러한 전략을 사용하여 외부 키를 정의할 수 있습니다:
파티션 ID를 공유하는 라우팅 테이블 간
동일한 파이프라인 계층 구조의 관계에 대해 partition_id 열을 공유할 수 있습니다.
다음처럼 외부 키 제약 조건을 정의하는 데 사용할 수 있습니다.
p_ci_pipelines:
- id
- partition_id
p_ci_builds:
- id
- partition_id
- pipeline_id
이 경우 p_ci_builds.partition_id는 빌드와 파이프라인의 파티션을 나타냅니다. 라우팅 테이블에 외부 키를 추가할 수 있습니다.
ALTER TABLE ONLY p_ci_builds
ADD CONSTRAINT fk_on_pipeline_and_partition
FOREIGN KEY (pipeline_id, partition_id)
REFERENCES p_ci_pipelines(id, partition_id) ON DELETE CASCADE;
서로 다른 파티션 ID를 가지는 라우팅 테이블 간
모든 CI 도메인의 관계에 대해 partition_id를 재사용하는 것은 불가능하므로 이 경우 값은 다른 속성으로 저장해야 합니다. 예를 들어 중복된 파이프라인을 취소할 때 새로운 파이프라인의 ID를 auto_canceled_by_id로 저장할 수 있습니다.
p_ci_pipelines:
- id
- partition_id
- auto_canceled_by_id
- auto_canceled_by_partition_id
이 경우 취소된 파이프라인이 취소된 파이프라인과 동일한 계층에 속하는지를 보장할 수는 없으므로 해당 파티션 및 외부 키는 다음과 같이 정의됩니다.
ALTER TABLE ONLY p_ci_pipelines
ADD CONSTRAINT fk_cancel_redundant_pipelines
FOREIGN KEY (auto_canceled_by_id, auto_canceled_by_partition_id)
REFERENCES p_ci_pipelines(id, partition_id) ON DELETE SET NULL;
라우팅 테이블 및 일반 테이블 간
CI 도메인의 모든 테이블이 파티션화되는 것은 아니기 때문에 라우팅 테이블이 비파티션화된 테이블을 참조하는 경우가 있습니다. 예를 들어 ci_pipelines에서 external_pull_requests를 참조합니다.
FOREIGN KEY (external_pull_request_id)
REFERENCES external_pull_requests(id)
ON DELETE SET NULL
이 경우 파티션 수준에서 FK 정의를 라우팅 테이블로 이동하여 새로운 파이프라인 파티션에서 사용할 수 있게 합니다.
ALTER TABLE p_ci_pipelines
ADD CONSTRAINT fk_external_request
FOREIGN KEY (external_pull_request_id)
REFERENCES external_pull_requests(id) ON DELETE SET NULL;
일반 테이블 및 라우팅 테이블 간
CI 도메인의 대부분의 테이블은 최소한 하나의 라우팅 테이블을 참조할 것이며, 예를 들어 ci_pipeline_messages가 ci_pipelines을 참조합니다. 이러한 정의는 라우팅 테이블을 사용하도록 업데이트해야 하며, 이를 위해 partition_id 열이 필요합니다.
p_ci_pipelines:
- id
- partition_id
ci_pipeline_messages:
- id
- pipeline_id
- pipeline_partition_id
다음과 같이 외부 키를 정의할 수 있습니다.
ALTER TABLE ci_pipeline_messages ADD CONSTRAINT fk_pipeline_partitioned
FOREIGN KEY (pipeline_id, pipeline_partition_id)
REFERENCES p_ci_pipelines(id, partition_id) ON DELETE CASCADE;
초기에 두 개의 파티션만 읽을 수 있도록 구현하여 제로 파티션을 분리할 수 있도록 합니다. 각 반복 단계에는 되돌릴(revert) 수 있는 전략이 있으며, 데이터베이스 변경 사항을 배포하기 전에 성능 테스트 환경에서 테스트하고자 합니다.
:: 신중한 반복을 통한 위험 감소
이러한 전략은 CI/CD 파티셔닝 구현 위험을 수용 가능한 수준으로 줄일 것으로 기대됩니다. 우리는 초기에 두 개의 파티션에서만 읽는 것에 중점을 둠으로써 운영 환경에서 문제가 발생할 경우 제로 파티션을 분리할 수 있도록 합니다. 이 문서에서 설명한 변경 사항을 안전하고 신뢰할 수 있는 방식으로 전달하는 것이 우리의 우선 순위입니다.
구현과 함께 전진해 나가면서 설계에 대해 추가로 반복하고 점진적으로 배포하고 문제가 발생한 경우 변경 사항을 쉽게 되돌릴(revert) 수 있는 방법을 찾아야 합니다. 데이터베이스 스키마 변경을 점진적으로 구현하는 것은 위험을 줄이는 가장 중요한 방법 중 하나이며, 운영 환경에 점진적으로 배포하는 것은 더 어려운 과제일 수 있습니다. 그러나 수행할 수 있으며, 우리가 여기서 꼭 필요로 하는 창의성을 요구할 수도 있습니다. 이는 다음과 같은 형태로 나타날 수 있습니다.
파티션 스키마의 점진적 적용
첫 번째 파티션 라우팅 테이블을 (아마도 p_ci_pipelines) 도입하고 그것의 제로 파티션 (ci_pipelines)을 연결하면 새로운 라우팅 테이블과 직접적인 파티션 대신에 상호작용을 시작해야 할 것입니다. 보통 Ci::Pipeline Rails 모델이 사용하는 데이터베이스 테이블을 self.table_name = 'p_ci_pipelines'와 같은 것으로 재정의할 것입니다. 불행히도 이 접근 방식은 증분적인 적용을 지원하지 않을 수 있습니다. 왜냐하면 self.table_name은 애플리케이션 부팅 시 읽힐 것이며, 나중에는 애플리케이션을 다시 시작하지 않고는 이 변경을 되돌릴 수 없을 수도 있습니다.
이를 해결하는 한 가지 방법은 Ci::Partitioned::Pipeline 모델을 도입하는 것일 수 있습니다. 이 모델에서는 self.table_name을 p_ci_pipeline로 설정하고, Ci::Pipeline.partitioned에서 그의 메타 클래스를 반환할 것입니다. 이것은 ci_pipelines에서 p_ci_pipelines로의 읽기를 간단한 되돌림 전략과 함께하는 피처 플래그를 사용할 수 있도록 할 것입니다.
파티션화된 읽기에 대한 점진적 실험
또 다른 예는 우리가 다른 파티션을 연결하기로 결정했을 때와 관련이 있을 것입니다. 단계 1의 목표는 파티션화된 스키마/라우팅 테이블당 두 개의 파티션을 갖는 것입니다. 즉, p_ci_pipelines의 경우 ci_pipelines를 제로 파티션으로 연결하고, 새로운 데이터를위한 ci_pipelines_p1 파티션을 만들 것입니다. p_ci_pipelines에서의 모든 읽기는 p1 파티션에서도 데이터를 읽어야 하며 우리는 또한 여러 파티션을 대상으로 한 읽기를 반복적으로 실험하여 파티션화의 성능과 오버헤드를 평가해야 합니다.
이를 위해 우리는 이전 데이터를 ci_pipelines_m1 (마이너스 1) 파티션으로 반복적으로 이동할 수 있습니다. 아마도 partition_id = 1을 만들고 몇 가지 정말 오래된 파이프라인을 거기로 이동할 것입니다. 그런 다음 m1 파티션으로 데이터를 반복적으로 이전하여 영향, 성능을 메트릭하고 새로운 파티션 p1을 (아직 만들어지지 않은) 데이터를 생성하기 전에 신뢰도를 높일 수 있습니다.
반복
우리는 먼저 단계 1의 반복에 초점을 맞추고 싶습니다. 이 반복의 목표와 주요 목적은 가장 큰 6개의 CI/CD 데이터베이스 테이블을 6개의 라우팅 테이블로 파티션화하고 12개의 파티션으로 만드는 것입니다. 이렇게 함으로써 우리의 Rails SQL 쿼리는 대부분 변경되지 않을 것이지만 데이터베이스 성능 저하가 발생할 경우 “제로 파티션”을 비상 분리할 수도 있게 될 것입니다. 이것은 사용자들에게 이전 데이터를 차단하겠지만 애플리케이션은 계속해서 가동되도록 할 것이며 이는 전체 애플리케이션 전체 장애보다는 더 나은 대안일 것입니다.
- 단계 0: CI/CD 데이터 파티션화 전략 구축: 완료. ✅
-
단계 1: 6개의 가장 큰 CI/CD 데이터베이스 테이블을 파티션화
- 모든 6개의 데이터베이스 테이블에 대해 파티션화된 스키마를 만듭니다.
- 모든 파티션화된 자원에
partition_id를 cascading하는 방법을 설계합니다. - 라우팅 테이블을 대상으로 하는 초기 쿼리 분석기를 구현합니다.
- 파티션된 데이터베이스 테이블에 제로 파티션을 연결합니다.
- 애플리케이션을 라우팅 테이블과 파티션화된 테이블을 대상으로 하도록 업데이트합니다.
- 이 솔루션의 성능과 효율성을 메트릭합니다.
되돌림 전략: 라우팅 테이블 대신 실제 파티션 사용으로 전환합니다.
-
단계 2: 파티션화된 테이블을 대상으로 SQL 쿼리에 파티션 키를 추가합니다.
- 파티션화된 테이블을 대상으로 하는 쿼리 분석기를 구현하여 쿼리가 올바른 파티션 키를 사용하고 있는지 확인합니다.
- 모든 기존 쿼리를 수정하여 모든 쿼리가 필터로 파티션 키를 사용하도록 합니다.
되돌림 전략: 피처 플래그, 쿼리별로.
-
단계 3: 새로운 파티션화된 데이터 액세스 패턴 구축
- 새로운 API를 빌드하거나 기존 API를 확장하여 시간 경과 데이터 보존 정책에 따라 제외되어야 하는 파티션에 저장된 데이터에 액세스 허용 되돌림 전략: 피처 플래그.
-
단계 4: 파티션 위에 구축된 시간 경과 메커니즘 도입
- 시간 경과 정책 메커니즘 구축
- GitLab.com에서 시간 경과 전략 활성화
-
단계 5: 파티션을 자동으로 만들기 위한 메커니즘 도입
- 자동으로 파티션을 만들 수 있도록 함
- 새 아키텍처를 Self-managed 인스턴스로 제공하기
아래 다이어그램은 위의 계획을 간트 차트로 시각화한 것입니다. 아래 차트의 날짜는 계획을 더 잘 시각화하기 위한 것으로, 이는 마감일이 아닙니다. 언제든지 변경될 수 있습니다.
결론
우리는 CI/CD 데이터의 파티션을 위한 견고한 전략을 구축하고자 합니다. 우리는 이 설계에 대한 반복이 어렵다는 사실을 알고 있습니다. 왜냐하면 멀티 테라바이트 규모의 PostgreSQL 인스턴스의 데이터베이스 스키마를 관리하는데 실수를 하면 잠재적인 다운타임 없이는 쉽게 되돌릴 수 없을 수도 있기 때문입니다. 이것이 우리가 파티션 전략을 연구하고 정제하는 데 상당한 시간을 할애하는 이유입니다. 또한, 이 문서에 기술된 전략 또한 반복의 대상입니다. 우리가 위험을 감소시키고 계획을 개선할 수 있는 더 나은 방법을 찾을 때마다, 이 문서를 업데이트해야 합니다.
대규모 데이터 이주를 피하는 방법을 찾았으며, CI/CD 데이터의 파티션에 대한 반복적인 전략을 구축하고 있습니다. 저희는 여기에 우리의 전략을 기록하여 지식을 공유하고 다른 팀원으로부터 피드백을 구하는 것이 목적입니다.
누가
책임 담당자:
| 역할 | 담당자 |
|---|---|
| 저자 | Grzegorz Bizon, 주임 엔지니어 |
| 추천자 | Kamil Trzciński, 시니어 주임 엔지니어 |
| 제품 리더십 | Jackie Porter, 제품 관리 총괄 |
| 엔지니어링 리더십 | Caroline Simpson, 엔지니어링 매니저 / Cheryl Li, 시니어 엔지니어링 매니저 |
| 리드 엔지니어 | Marius Bobin, 시니어 백엔드 엔지니어 |
| 시니어 엔지니어 | Maxime Orefice, 시니어 백엔드 엔지니어 |
| 시니어 엔지니어 | Tianwen Chen, 시니어 백엔드 엔지니어 |