- 기본 문제 해결
-
PostgreSQL 데이터베이스 복제 오류 수정
- 비활성 복제 슬롯 제거
- 메시지:
WARNING: oldest xmin is far in the past및pg_wal크기 증가 - 메시지:
ERROR: replication slots can only be used if max_replication_slots > 0? - 메시지:
FATAL: could not start WAL streaming: ERROR: replication slot "geo_secondary_my_domain_com" does not exist? - 메시지: “Command exceeded allowed execution time”을 설정해 대 복제?
- 메시지: “PANIC: could not write to file
pg_xlog/xlogtemp.123: No space left on device” - 메시지: “ERROR: canceling statement due to conflict with recovery”
- 메시지:
FATAL: could not connect to the primary server: server certificate for "PostgreSQL" does not match host name - 메시지:
LOG: invalid CIDR mask in address - 메시지:
LOG: invalid IP mask "md5": Name or service not known - 메시지:
gitlab-ctl replicate-geo-database실행시gitlabhq_production데이터베이스에서 데이터를 찾음 - 메시지:
FATAL: could not map anonymous shared memory: Cannot allocate memory
-
동기화 오류
- 모든 업로드 다시 확인(또는 확인된 SSF 데이터 유형)
-
메시지:
동기화 실패 - 리포지터리 동기화 오류 - 백필 중 실패
- 동기화 실패 메시지: “검증이 다음과 같이 실패함: 검증 중 오류: 파일이 체크섬을 생성할 수 없는 파일”
- 메시지: curl 18 transfer closed with outstanding read data remaining & fetch-pack: unexpected disconnect while reading sideband packet
- 프로젝트 또는 프로젝트 위키 리포지터리
- Geo 보조 사이트에서의 리포지터리 확인 실패 찾기
- PostgreSQL 이외의 복제 실패 수정
- HTTP 응답 코드 오류
-
일반 오류 해결
- Geo 데이터베이스 구성 파일이 없음
- 기존 추적 데이터베이스를 재사용할 수 없음
- Geo 사이트에 쓰기 가능한 데이터베이스가 있어 기본 사이트와의 복제가 구성되지 않았음을 나타냄
- Geo 사이트가 기본 사이트로부터 데이터베이스를 복제하는 것으로 보이지 않음
- Geo 데이터베이스 버전 (…)이(가) 최신 마이그레이션(…)과(와) 일치하지 않음
- GitLab에서 리포지터리의 100% 이상이 동기화되었다는 메시지가 표시됨
primary사이트의external_url값을 변경한 후 UI에서Unhealthy로 나타난 보조 사이트- 백업 중
ERROR: canceling statement due to conflict with recovery메시지
- 장애 조치 중 오류 수정 또는 보조를 기본 사이트로 전환 중입니다
- 클라이언트 오류 수정
- 부분 장애 복구
- 데이터베이스 복제 지연의 원인 조사
- Geo Secondary 사이트의 복제 재설정
Geo 문제 해결
Geo 설정에는 세부 사항에 주의를 기울여야 하며 때로는 한 단계를 놓칠 수도 있습니다.
다음은 문제를 해결하려는 시도해야 할 단계 디렉터리입니다:
기본 문제 해결
더 고급 문제 해결을 시도하기 전에:
Geo 사이트의 상태 확인
기본 사이트에서:
- 왼쪽 사이드바에서 아래쪽에서 관리자 영역(Admin Area)을 선택합니다.
- Geo > 사이트를 선택합니다.
우리는 각 보조 사이트에서 다음과 같은 상태 확인을 수행하여 문제를 식별하는 데 도움을 줍니다:
- 사이트가 실행 중인가요?
- 보조 사이트의 데이터베이스가 스트리밍 복제로 구성되었나요?
- 보조 사이트의 추적 데이터베이스가 구성되었나요?
- 보조 사이트의 추적 데이터베이스가 연결되었나요?
- 보조 사이트의 추적 데이터베이스가 최신 상태인가요?
- 보조 사이트의 상태가 10분 미만으로 최근인가요?
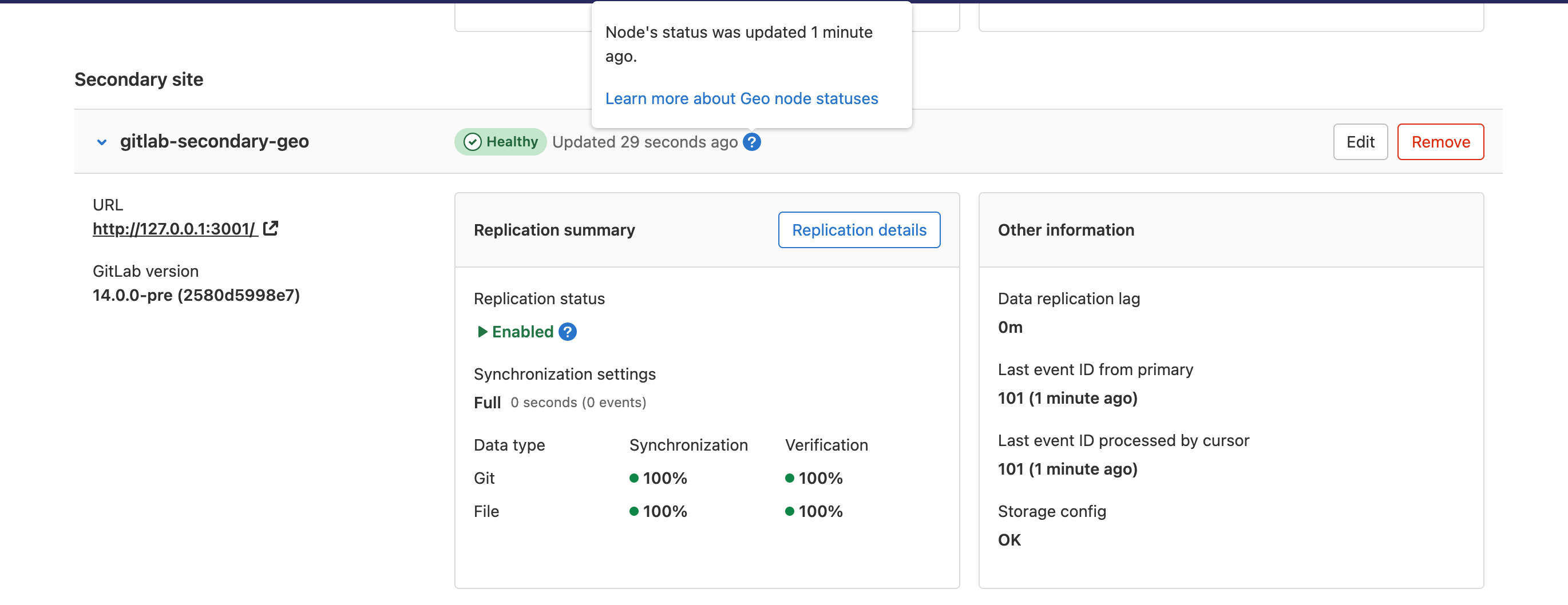
사이트의 상태가 10분 이상 된 경우 사이트는 “Unhealthy”로 표시됩니다. 이 경우 해당 보조 사이트의 Rails 콘솔에서 다음을 실행해 보세요:
Geo::MetricsUpdateWorker.new.perform
에러가 발생하면 이 에러가 작업을 완료하는 데도 방해되고 있을 수 있습니다. 10분 이상 걸리면 성능 문제가 있을 수 있으며, 상태가 최종적으로 업데이트되더라도 UI에서 항상 “Unhealthy”로 표시될 수 있습니다.
상태가 성공적으로 업데이트되면 Sidekiq에 문제가 발생할 수 있습니다. 실행 중인가요? 로그에 오류가 표시되나요? 이 작업은 매분마다 enqueued되어야 하며 작업 중복성 이더펀던시(idempotency) 키를 지우지 않았다면 제대로 실행되지 않을 수 있습니다. 이는 Redis에서 독점 레이스를 사용하여 한 번에 한 작업만 실행될 수 있도록 보장합니다. 기본 사이트는 PostgreSQL 데이터베이스에서 상태를 직접 업데이트합니다. 보조 사이트에서는 상태 데이터를 포함한 HTTP POST 요청을 기본 사이트에 보냅니다.
특정 상태 확인이 실패하면 사이트도 “Unhealthy”로 표시됩니다. 해당 보조 사이트의 Rails 콘솔에서 다음을 실행하여 실패 사항을 확인할 수 있습니다:
Gitlab::Geo::HealthCheck.new.perform_checks
반환 값이 "" (빈 문자열) 또는 "Healthy"인 경우 확인이 성공한 것입니다. 다른 값이 반환되면 해당 메시지가 실패 사유를 설명하거나 익셉션 메시지가 표시될 것입니다.
사용자 인터페이스에서 보고된 일반 오류 메시지를 해결하는 방법에 대한 정보는 일반적인 오류 수정을 참조하세요.
사용자 인터페이스가 작동하지 않거나 로그인할 수 없는 경우 Geo 상태 확인을 매뉴얼으로 실행하여 이 정보와 몇 가지 자세한 내용을 얻을 수 있습니다.
상태 확인 Rake 작업
이 Rake 작업은 기본 또는 보조 Geo 사이트의 Rails 노드에서 실행할 수 있습니다:
sudo gitlab-rake gitlab:geo:check
예시 출력:
Geo 확인 중 ...
GitLab Geo 사용 가능 ... 예
GitLab Geo 활성화됨 ... 예
이 머신의 Geo 노드 이름이 데이터베이스 레코드와 일치합니다 ... 예, "Shanghai"라는 보조 노드를 찾았습니다
GitLab Geo 추적 데이터베이스가 올바르게 구성되었습니까? ... 예
데이터베이스 복제가 활성화되었나요? ... 예
데이터베이스 복제가 작동하나요? ... 예
GitLab Geo HTTP(S) 연결 ...
* 기본 노드에 연결할 수 있나요 ... 예
HTTP/HTTPS 리포지터리 복제가 활성화되었나요 ... 예
머신 시계가 동기화되었나요 ... 예
Git 사용자에게 기본 SSH 구성이 있나요? ... 예
OpenSSH가 AuthorizedKeysCommand를 사용하도록 구성되었나요 ... 예
새 프로젝트를 해시 리포지터리에 저장하도록 GitLab이 구성되어 있나요? ... 예
모든 프로젝트가 해시 리포지터리에 있나요? ... 예
Geo 확인 중 ... 완료
환경 변수를 사용하여 사용자 지정 NTP 서버를 지정할 수도 있습니다. 예:
sudo gitlab-rake gitlab:geo:check NTP_HOST="ntp.ubuntu.com" NTP_TIMEOUT="30"
다음과 같은 환경 변수가 지원됩니다.
| 변수 | 설명 | 기본 값 |
|---|---|---|
NTP_HOST
| NTP 호스트입니다. | pool.ntp.org
|
NTP_PORT
| 호스트가 수신 대기하는 NTP 포트입니다. | ntp
|
NTP_TIMEOUT
| 초 단위의 NTP 타임아웃입니다. |
net-ntp에서 정의된 값 (60 seconds).
|
Rake 작업이 OpenSSH가 AuthorizedKeysCommand를 사용하도록 구성되었나요 확인을 건너뛰는 경우 다음 출력을 표시합니다:
OpenSSH가 AuthorizedKeysCommand를 사용하도록 구성되었나요 ... 스킵됨
이유:
OpenSSH 구성 파일에 액세스할 수 없습니다
다음을 시도해 보세요:
이는 SELinux를 사용하는 경우 예상되는 동작입니다. 매뉴얼으로 구성을 확인할 수 있습니다.
자세한 정보는 다음을 참조하세요:
doc/administration/operations/fast_ssh_key_lookup.md
이 문제는 다음과 같은 경우가 발생할 수 있습니다:
- SELinux를 사용하는 경우.
- SELinux를 사용하지 않고
git사용자가 제한된 파일 권한으로 인해 OpenSSH 구성 파일에 액세스할 수 없는 경우.
후자의 경우 다음 출력에서 root 사용자만이 이 파일을 읽을 수 있음을 보여줍니다:
sudo stat -c '%G:%U %A %a %n' /etc/ssh/sshd_config
root:root -rw------- 600 /etc/ssh/sshd_config
파일 소유자 또는 권한을 변경하지 않고도 git 사용자가 OpenSSH 구성 파일을 읽을 수 있도록 하려면 acl을 사용하세요:
sudo setfacl -m u:git:r /etc/ssh/sshd_config
동기화 상태 Rake 작업
현재의 동기화 정보는 Geo secondary 사이트의 Rails를 실행하는 노드(Puma, Sidekiq 또는 Geo Log Cursor)에서 이 Rake 작업을 매뉴얼으로 실행함으로써 찾을 수 있습니다.
GitLab은 Object Storage에 저장된 오브젝트를 확인하지 않습니다. Object Storage를 사용하는 경우 “확인됨” 확인에서 모든 항목이 0으로 표시됩니다. 이는 예상되는 동작이며 걱정할 필요가 없습니다.
sudo gitlab-rake geo:status
출력에는 다음이 포함됩니다.
- “실패” 항목의 개수(있는 경우)
- “성공” 항목의 “총” 대비 퍼센트
예시:
http://secondary.example.com/
-----------------------------------------------------
GitLab Version: 14.9.2-ee
Geo Role: Secondary
Health Status: Healthy
Project Repositories: succeeded 12345 / total 12345 (100%)
Project Wiki Repositories: succeeded 6789 / total 6789 (100%)
Attachments: succeeded 4 / total 4 (100%)
CI job artifacts: succeeded 0 / total 0 (0%)
Design management repositories: succeeded 1 / total 1 (100%)
LFS Objects: failed 1 / succeeded 2 / total 3 (67%)
Merge Request Diffs: succeeded 0 / total 0 (0%)
Package Files: failed 1 / succeeded 2 / total 3 (67%)
Terraform State Versions: failed 1 / succeeded 2 / total 3 (67%)
Snippet Repositories: failed 1 / succeeded 2 / total 3 (67%)
Group Wiki Repositories: succeeded 4 / total 4 (100%)
Pipeline Artifacts: failed 3 / succeeded 0 / total 3 (0%)
Pages Deployments: succeeded 0 / total 0 (0%)
Repositories Checked: failed 5 / succeeded 0 / total 5 (0%)
Package Files Verified: succeeded 0 / total 10 (0%)
Terraform State Versions Verified: succeeded 0 / total 10 (0%)
Snippet Repositories Verified: succeeded 99 / total 100 (99%)
Pipeline Artifacts Verified: succeeded 0 / total 10 (0%)
Project Repositories Verified: succeeded 12345 / total 12345 (100%)
Project Wiki Repositories Verified: succeeded 6789 / total 6789 (100%)
Sync Settings: Full
Database replication lag: 0 seconds
Last event ID seen from primary: 12345 (2분 전)
Last event ID processed: 12345 (2분 전)
Last status report was: 1분 전
각 항목에는 최대 세 가지 상태가 있을 수 있습니다. 예를 들어 Project Repositories의 경우 다음과 같은 줄이 표시됩니다:
Project Repositories: succeeded 12345 / total 12345 (100%)
Project Repositories Verified: succeeded 12345 / total 12345 (100%)
Repositories Checked: failed 5 / succeeded 0 / total 5 (0%)
3가지 상태 항목의 정의는 다음과 같습니다:
-
Project Repositories출력은 얼마나 많은 프로젝트 리포지터리가 Primary에서 Secondary로 동기화되었는지를 보여줍니다. -
Project Verified Repositories출력은 이 Secondary의 프로젝트 리포지터리 중 Primary와 일치하는 리포지터리 체크섬을 가지고 있는지를 보여줍니다. -
Repositories Checked출력은 Secondary에서 로컬 Git 리포지터리 체크(git fsck)를 통과한 프로젝트 리포지터리의 수를 보여줍니다.
실패한 항목에 대한 자세한 내용을 찾으려면 여기를 확인하세요.
복제 또는 확인 실패를 알리는 경우 이를 해결해볼 수 있습니다.
리포지터리 체크 실패가 있는 경우 해결해볼 수 있습니다.
Geo 확인 Rake 작업을 실행할 때 발견된 오류 수정
이 Rake 작업을 실행할 때 노드가 올바르게 구성되지 않은 경우 오류 메시지를 볼 수 있습니다.
sudo gitlab-rake gitlab:geo:check
-
Rails가 데이터베이스에 연결할 때 암호를 제공하지 않았습니다.
Geo 체크 중... GitLab Geo 사용 가능... Exception: fe_sendauth: no password supplied GitLab Geo 활성화됨... Exception: fe_sendauth: no password supplied ... Geo 체크 완료됨gitlab_rails['db_password']가postgresql['sql_user_password']의 해시를 생성할 때 사용한 일반 텍스트 암호로 설정되어 있는지 확인하세요. -
Rails가 데이터베이스에 연결할 수 없습니다.
Geo 체크 중... GitLab Geo 사용 가능... Exception: FATAL: no pg_hba.conf entry for host "1.1.1.1", user "gitlab", database "gitlabhq_production", SSL on FATAL: no pg_hba.conf entry for host "1.1.1.1", user "gitlab", database "gitlabhq_production", SSL off GitLab Geo 활성화됨... Exception: FATAL: no pg_hba.conf entry for host "1.1.1.1", user "gitlab", database "gitlabhq_production", SSL on FATAL: no pg_hba.conf entry for host "1.1.1.1", user "gitlab", database "gitlabhq_production", SSL off ... Geo 체크 완료됨postgresql['md5_auth_cidr_addresses']에 레일스 노드의 IP 주소가 포함되어 있는지 확인하세요. 또한, IP 주소에 서브넷 마스크가 포함되어 있는지 확인하세요:postgresql['md5_auth_cidr_addresses'] = ['1.1.1.1/32']. -
Rails가 잘못된 암호를 제공하였습니다.
Geo 체크 중... GitLab Geo 사용 가능... Exception: FATAL: password authentication failed for user "gitlab" FATAL: password authentication failed for user "gitlab" GitLab Geo 활성화됨... Exception: FATAL: password authentication failed for user "gitlab" FATAL: password authentication failed for user "gitlab" ... Geo 체크 완료됨gitlab_rails['db_password']에 정확한 암호가 설정되어 있는지 확인하세요.gitlab-ctl pg-password-md5 gitlab을 실행하고 암호를 입력하여postgresql['sql_user_password']에 해시를 만들었는지 확인하세요. -
체크가
secondary node가 아님을 반환합니다.Geo 체크 중... GitLab Geo 사용 가능... yes GitLab Geo 활성화됨... yes GitLab Geo 추적 데이터베이스가 올바르게 구성됨... secondary node가 아님 Database 복제 활성화됨? ... secondary node가 아님 ... Geo 체크 완료됨관리 영역에서 Geo > Sites 아래 primary 사이트 웹 인터페이스에 secondary 사이트를 추가했는지 확인하세요. 또한, primary 사이트의 관리 영역에서 secondary 사이트를 편집하여
Name필드에 후행 슬래시(/)가 있는지 확인하세요(GitLab 12.3 이전 버전에서). -
체크가
Exception: PG::UndefinedTable: ERROR: relation "geo_nodes" does not exist을 반환합니다.Geo 체크 중... GitLab Geo 사용 가능... no 이를 해결하세요: GitLab Geo 기능이 포함된 새 라이선스를 추가하세요 자세한 정보는: https://about.gitlab.com/features/gitlab-geo/ GitLab Geo 활성화됨... Exception: PG::UndefinedTable: ERROR: relation "geo_nodes" does not exist LINE 8: WHERE a.attrelid = '"geo_nodes"'::regclass ^ : SELECT a.attname, format_type(a.atttypid, a.atttypmod), pg_get_expr(d.adbin, d.adrelid), a.attnotnull, a.atttypid, a.atttypmod, c.collname, col_description(a.attrelid, a.attnum) AS comment FROM pg_attribute a LEFT JOIN pg_attrdef d ON a.attrelid = d.adrelid AND a.attnum = d.adnum LEFT JOIN pg_type t ON a.atttypid = t.oid LEFT JOIN pg_collation c ON a.attcollation = c.oid AND a.attcollation <> t.typcollation WHERE a.attrelid = '"geo_nodes"'::regclass AND a.attnum > 0 AND NOT a.attisdropped ORDER BY a.attnum ... Geo 체크 완료됨PostgreSQL 주 버전(9 > 10)을 수행하고 있는 경우에는 이를 업데이트해야 합니다. 복제 프로세스 시작를 따르세요.
-
Rails가 Geo 추적 데이터베이스에 연결할 필요한 구성을 가지고 있지 않은 것으로 보입니다.
Geo 체크 중... GitLab Geo 사용 가능... yes GitLab Geo 활성화됨... yes GitLab Geo 추적 데이터베이스가 올바르게 구성됨... no 이를 해결하세요: Rails는 Geo 추적 데이터베이스에 연결할 필요한 구성을 가지고 있지 않은 것으로 보입니다. 추적 데이터베이스가 이 노드와 다른 노드에서 실행 중이면 구성을 추가해야 할 수 있습니다. ... Geo 체크 완료됨- 모든 서비스의 노드에서 보조 사이트를 실행 중인 경우, Geo 데이터베이스 복제 - 보조 서버 구성을 따르세요.
- 보조 사이트의 추적 데이터베이스를 별도의 노드에서 실행 중인 경우, 다중 서버용 Geo - 보조 Geo 사이트에서 Geo 추적 데이터베이스 구성을 따르세요.
- 보조 사이트의 추적 데이터베이스를 Patroni 클러스터에서 실행 중인 경우, Geo 데이터베이스 복제 - 추적 PostgreSQL 데이터베이스를 위한 Patroni 클러스터 구성을 따르세요.
- 보조 사이트의 추적 데이터베이스를 외부 데이터베이스에서 실행 중인 경우, 외부 PostgreSQL 인스턴스 사용하기을 따르세요.
- GitLab Rails 앱(Puma, Sidekiq 또는 Geo Log Cursor)을 실행하는 서비스가 아닌 노드에서 Geo 체크 작업을 실행한 경우 이 오류는 무시할 수 있습니다. 노드에서는 Rails을 구성할 필요가 없습니다.
메시지: 머신 클록이 동기화되었습니다 … 예외
Rake 작업은 서버 클록이 NTP와 동기화되어 있는지 확인하려고 시도합니다. 동기화된 클록은 Geo가 올바르게 작동하는 데 필요합니다. 예를 들어, 보안을 위해, 주 사이트와 보조 사이트의 서버 시간이 1분 이상 차이 나면 Geo 사이트 간 요청이 실패합니다. 이 확인 작업이 시간 불일치 이외의 이유로 완료되지 않으면 Geo가 작동하지 않을 수 있는 것은 아닙니다.
이 확인 작업을 수행하는 Ruby gem은 참조 시간 원본으로 pool.ntp.org를 하드코딩했습니다.
-
예외 메시지
머신 클록이 동기화되었습니다 ... 예외: Timeout::Error이 문제는 서버가
pool.ntp.org호스트에 액세스할 수 없을 때 발생합니다. -
예외 메시지
머신 클록이 동기화되었습니다 ... 예외: 호스트로의 경로 없음 - recvfrom(2)이 문제는 호스트 이름인
pool.ntp.org가 시간 서비스를 제공하지 않는 서버로 변환될 때 발생합니다.
이 경우, GitLab 15.7 이상에서는 환경 변수를 사용하여 사용자 정의 NTP 서버를 지정할 수 있습니다.
GitLab 15.6 이하에서는 다음 중 하나의 해결책을 사용하세요:
-
/etc/hosts에pool.ntp.org항목을 추가하여 요청을 유효한 로컬 시간 서버로 직접 지정합니다. 이렇게 하면 긴 타임아웃 및 타임아웃 오류가 해결됩니다. - 확인 작업을 유효한 IP 주소로 직접 지정합니다. 이렇게 하면 타임아웃 문제는 해결되지만 위에서 언급한대로
호스트로의 경로 없음오류가 발생합니다.
클라우드 네이티브 GitLab 배포는 쿠버네티스의 컨테이너가 호스트 클록에 액세스할 수 없기 때문에 오류가 발생합니다:
머신 클록이 동기화되었습니다 ... 예외: getaddrinfo: Servname not supported for ai_socktype
메시지: ActiveRecord::StatementInvalid: PG::ReadOnlySqlTransaction: ERROR: cannot execute INSERT in a read-only transaction
이 오류가 보조 사이트에서 발생하면 gitlab-rails 또는 gitlab-rake 명령뿐만 아니라 Puma, Sidekiq 및 Geo Log Cursor 서비스의 모든 사용에 영향을 미칩니다.
ActiveRecord::StatementInvalid: PG::ReadOnlySqlTransaction: ERROR: cannot execute INSERT in a read-only transaction
/opt/gitlab/embedded/service/gitlab-rails/app/models/application_record.rb:86:in `block in safe_find_or_create_by'
/opt/gitlab/embedded/service/gitlab-rails/app/models/concerns/cross_database_modification.rb:92:in `block in transaction'
/opt/gitlab/embedded/service/gitlab-rails/lib/gitlab/database.rb:332:in `block in transaction'
/opt/gitlab/embedded/service/gitlab-rails/lib/gitlab/database.rb:331:in `transaction'
/opt/gitlab/embedded/service/gitlab-rails/app/models/concerns/cross_database_modification.rb:83:in `transaction'
/opt/gitlab/embedded/service/gitlab-rails/app/models/application_record.rb:86:in `safe_find_or_create_by'
/opt/gitlab/embedded/service/gitlab-rails/app/models/shard.rb:21:in `by_name'
/opt/gitlab/embedded/service/gitlab-rails/app/models/shard.rb:17:in `block in populate!'
/opt/gitlab/embedded/service/gitlab-rails/app/models/shard.rb:17:in `map'
/opt/gitlab/embedded/service/gitlab-rails/app/models/shard.rb:17:in `populate!'
/opt/gitlab/embedded/service/gitlab-rails/config/initializers/fill_shards.rb:9:in `<top (required)>'
/opt/gitlab/embedded/service/gitlab-rails/config/environment.rb:7:in `<top (required)>'
/opt/gitlab/embedded/bin/bundle:23:in `load'
/opt/gitlab/embedded/bin/bundle:23:in `<main>'
PostgreSQL 읽기 전용 레플리카 데이터베이스가 이러한 오류를 생성할 수 있습니다:
2023-01-17_17:44:54.64268 ERROR: cannot execute INSERT in a read-only transaction
2023-01-17_17:44:54.64271 STATEMENT: /*application:web,db_config_name:main*/ INSERT INTO "shards" ("name") VALUES ('storage1') RETURNING "id"
이 상황은 보조 사이트가 아직 자신이 보조 사이트임을 알지 못하는 초기 구성 중에 발생할 수 있습니다.
오류를 해결하려면 단계 3. 보조 사이트 추가를 따르세요.
PostgreSQL 복제가 작동하는지 확인
PostgreSQL 복제가 작동하는지 확인하려면 다음을 확인하세요:
사이트가 올바른 데이터베이스 노드를 가리키는지?
주 Geo 사이트가 쓰기 권한이 있는 데이터베이스 노드를 가리키도록 해야 합니다.
모든 보조 사이트는 읽기 전용 데이터베이스 노드를 가리켜야 합니다.
Geo가 현재 사이트를 올바르게 감지할 수 있는지?
Geo는 /etc/gitlab/gitlab.rb에서 다음 논리로 현재 Puma 또는 Sidekiq 노드의 Geo 사이트 이름을 찾습니다.
- “Geo 노드 이름”을 가져옵니다 (설정을 “Geo 사이트 이름”으로 이름 바꾸는 이슈가 있음):
- Linux 패키지:
gitlab_rails['geo_node_name']설정을 가져옵니다. - GitLab 헬름 차트:
global.geo.nodeName설정을 가져옵니다(GitLab Geo와 함께 사용하는 차트 참조).
- Linux 패키지:
- 그것이 정의되지 않으면
external_url설정을 가져옵니다.
이 이름은 Geo 사이트 대시보드에서 이름과 일치하는 Geo 사이트를 조회하는 데 사용됩니다.
현재 머신에 사이트 이름과 해당하는 데이터베이스 레코드가 주인지 보조인지 표시하려면 다음 확인 작업을 실행하세요:
sudo gitlab-rake gitlab:geo:check
현재 머신의 사이트 이름과 일치하는 데이터베이스 레코드가 주 또는 보조 사이트인지 표시됩니다.
이 머신의 Geo 노드 이름이 데이터베이스 레코드와 일치함 ... 예, "Shanghai"라는 보조 노드를 찾음
이 머신의 Geo 노드 이름이 데이터베이스 레코드와 일치함 ... 아니요
해결 방법:
Geo 노드 데이터베이스 레코드를 추가하거나 업데이트하여 이름을 "https://example.com/"로 설정합니다.
또는 해당 머신의 Geo 노드 이름을 기존 데이터베이스 레코드의 이름과 일치하도록 설정할 수 있습니다: "London", "Shanghai"
자세한 정보는 다음 위치에서 확인하세요:
doc/administration/geo/replication/troubleshooting.md#can-geo-detect-the-current-node-correctly
이름 필드 설명에서 권장 사이트 이름에 대한 자세한 정보는 Geo 관리 영역 공통 설정을 참조하세요.
OS 로캘 데이터 호환성 확인
Geo 사이트 전체에 서로 다른 운영 체제나 다른 운영 체제 버전이 배포되었다면 Geo를 설정하기 전에 로캘 데이터 호환성 검사를 수행해야 합니다.
Geo는 PostgreSQL과 스트리밍 복제를 사용하여 Geo 사이트 전체에 데이터를 복제합니다. PostgreSQL은 텍스트 정렬을 위해 운영 체제의 C 라이브러리에서 제공하는 로캘 데이터를 사용합니다. Geo 사이트 전체의 C 라이브러리에 있는 로캘 데이터가 호환되지 않으면, 부정확한 쿼리 결과를 초래하여 보조 사이트에서 잘못된 동작을 일으킵니다.
예를 들어, Ubuntu 18.04 (그리고 그 이전 버전) 및 RHEL/Centos7 (그리고 그 이전 버전)은 해당 운영 체제의 후속 릴리스와 호환되지 않습니다. 더 많은 세부 정보는 PostgreSQL 위키를 참조하십시오.
Geo 사이트 전체의 모든 PostgreSQL을 실행하는 호스트에서 다음 셸 명령을 실행하십시오:
( echo "1-1"; echo "11" ) | LC_COLLATE=en_US.UTF-8 sort
출력은 다음과 같아야 합니다:
1-1
11
또는 반대 순서일 수 있습니다:
11
1-1
모든 호스트에서 출력이 동일하면, 호스트들은 호환되는 버전의 로캘 데이터를 사용 중이므로 Geo 구성을 진행할 수 있습니다.
만약 어떤 호스트에서 출력이 다르면, PostgreSQL 복제는 제대로 작동하지 않을 것입니다: 데이터베이스 복제본의 인덱스가 손상될 것입니다. 이 경우 호환되는 운영 체제 버전을 선택해야 합니다.
이미 디스크에 존재하는 데이터가 호환되지 않는 로캘을 사용하는 운영 체제로 이전되거나 복제를 통해 이전된 경우, 완전한 인덱스 재구성이 필요합니다.
GitLab 배포를 혼합해서 사용하는 경우에도 이 검사가 필요합니다. 로캘은 Linux 패키지 설치, GitLab 도커 컨테이너, Helm 차트 배포 또는 외부 데이터베이스 서비스 간에 다를 수 있습니다.
PostgreSQL 데이터베이스 복제 오류 수정
다음 섹션에서는 Database replication working? ... no로 표시된 복제 오류 메시지를 해결하기 위한 문제 해결 단계를 개요로 설명합니다(geo:check 출력에서 표시됨).
여기에 제공된 지침은 주로 단일 노드 Geo Linux 패키지 배포를 가정하고 있으며, 다른 환경에 맞게 조정되어야 할 수 있습니다.
비활성 복제 슬롯 제거
복제 슬롯은 복제 클라이언트(보조 사이트)가 해당 슬롯에서 연결을 해제할 때 ‘비활성’으로 표시됩니다. 비활성 복제 슬롯은 보조 사이트가 다시 연결하여 슬롯이 다시 활성화될 때 해당 클라이언트로부터 WAL 파일을 보존하게 합니다. 만약 보조 사이트가 다시 연결할 수 없는 상태라면, 해당 비활성 복제 슬롯을 제거하기 위해 다음 단계를 사용하십시오:
-
Geo 프라이머리 사이트의 데이터베이스 노드에서 PostgreSQL 콘솔 세션을 시작하십시오:
sudo gitlab-psql -d gitlabhq_production복제 슬롯 관리에 관리자 권한이 필요하여gitlab-rails dbconsole을 사용할 수 없습니다. -
복제 슬롯을 확인하고 그것들이 비활성인 경우 제거하십시오:
SELECT * FROM pg_replication_slots;active가f인 슬롯은 비활성입니다.- 해당 슬롯이 활성화되어야 하는 경우, 해당 슬롯을 사용하여 구성된 보조 사이트가 있는지 확인하고, 복제가 실행되지 않는 이유를 확인하기 위해 보조 사이트의 PostgreSQL 로그를 확인하십시오.
-
해당 슬롯을 더 이상 사용하지 않는 경우(예: 더 이상 Geo가 사용되지 않는 경우) 또는 보조 사이트가 다시 연결할 수 없는 경우, PostgreSQL 콘솔 세션을 사용하여 해당 슬롯을 제거해야 합니다:
SELECT pg_drop_replication_slot('<name_of_inactive_slot>');
-
이것이 더 이상 필요하지 않은 경우 해당 Geo 사이트를 제거하거나, 적절하게 복제 슬롯을 다시 만드는 복제 과정을 초기화해야 합니다.
메시지: WARNING: oldest xmin is far in the past 및 pg_wal 크기 증가
복제 슬롯이 비활성 상태인 경우, 해당 슬롯에 해당하는 pg_wal 로그는 영원히 보존됩니다
(또는 해당 슬롯이 다시 활성화될 때까지). 이는 지속적인 디스크 사용량 증가를 초래하며,
다음과 같은 메시지가 PostgreSQL 로그에서 반복적으로 표시됩니다:
WARNING: oldest xmin is far in the past
HINT: Close open transactions soon to avoid wraparound problems.
You might also need to commit or roll back old prepared transactions, or drop stale replication slots.
이를 해결하기 위해 비활성 복제 슬롯을 제거하고 복제를 다시 초기화해야 합니다.
메시지: ERROR: replication slots can only be used if max_replication_slots > 0?
이는 프라이머리 데이터베이스에서 max_replication_slots PostgreSQL 변수를 설정해야 함을 의미합니다. 이 설정은 기본적으로 1로 설정되어 있습니다. 만약 더 많은 보조 사이트가 있는 경우에는 이 값을 증가시켜야 할 수 있습니다.
이 설정이 적용되려면 PostgreSQL을 다시 시작해야 합니다. 자세한 내용은 PostgreSQL 복제 설정 가이드를 참조하십시오.
메시지: FATAL: could not start WAL streaming: ERROR: replication slot "geo_secondary_my_domain_com" does not exist?
이는 PostgreSQL에 해당 이름의 보조 사이트를 위한 복제 슬롯이 없을 때 발생합니다.
이 경우 보조 사이트에서 복제 프로세스를 다시 실행해야 할 것입니다.
메시지: “Command exceeded allowed execution time”을 설정해 대 복제?
이는 보조 사이트에서 복제 프로세스를 초기화하는 동안에 발생할 수 있으며, 초기 데이터셋이 기본 제한 시간(30분)에 복제될 수 있는 크기를 초과할 때 발생합니다.
gitlab-ctl replicate-geo-database를 다시 실행하되, --backup-timeout에 대해 더 큰 값을 포함하시기 바랍니다.:
sudo gitlab-ctl \
replicate-geo-database \
--host=<primary_node_hostname> \
--slot-name=<secondary_slot_name> \
--backup-timeout=21600
이렇게 하면 초기 복제가 기본 30분이 아닌 최대 6시간까지 완료될 수 있으며, 설치에 따라 조정하십시오.
메시지: “PANIC: could not write to file pg_xlog/xlogtemp.123: No space left on device”
Primary 데이터베이스에 사용되지 않는 복제 슬롯이 있는지 확인하십시오. 이는 pg_xlog에 대규모 로그 데이터가 쌓일 수 있기 때문입니다.
비활성 슬롯을 제거함으로써 pg_xlog에서 사용되는 공간을 줄일 수 있습니다.
메시지: “ERROR: canceling statement due to conflict with recovery”
이 오류 메시지는 일반적인 사용에서는 드물게 발생하며, 시스템은 회복할 만큼 강력합니다.
그러나 특정 조건에서는 일부 보조 데이터베이스의 쿼리가 과도하게 길어져 이 오류 메시지의 발생 빈도가 증가합니다. 이로 인해 다중 복제에서 모든 쿼리가 취소되어 완료되지 않을 수 있습니다.
이러한 장기 실행 쿼리는 앞으로 제거할 예정입니다만, 현재 해결책으로는 hot_standby_feedback 기능을 활성화하는 것을 권장합니다. 이로써 VACUUM이 최근에 삭제된 행을 제거하지 못하게 하여 primary 사이트에 블로트(bloat)가 발생할 가능성이 높아집니다. 그러나 GitLab.com에서 이를 사용하여 제품 라인에서 성공적으로 사용되었습니다.
hot_standby_feedback를 활성화하려면 secondary 사이트의 /etc/gitlab/gitlab.rb에 다음을 추가하십시오:
postgresql['hot_standby_feedback'] = 'on'
그런 다음 GitLab을 재구성하십시오:
sudo gitlab-ctl reconfigure
이 문제를 해결하는 데 도움이 되기 위해 이 문제에 댓글을 작성해 보십시오.
메시지: FATAL: could not connect to the primary server: server certificate for "PostgreSQL" does not match host name
이는 리눅스 패키지가 자동으로 생성하는 PostgreSQL 인증서가 공통 이름인 PostgreSQL을 포함하고 있지만, 복제는 다른 호스트에 연결하고 GitLab은 기본적으로 verify-full SSL 모드를 사용하려고 하기 때문에 발생합니다.
이 문제를 해결하려면 다음 중 하나를 선택할 수 있습니다:
-
--sslmode=verify-ca인자를replicate-geo-database명령과 함께 사용합니다. - 이미 복제된 데이터베이스의 경우
/var/opt/gitlab/postgresql/data/gitlab-geo.conf에서sslmode=verify-full을sslmode=verify-ca로 변경하고gitlab-ctl restart postgresql을 실행합니다. - 자동으로 생성된 인증서 대신에 사용 중인 호스트 이름을 CN 또는 SAN에 포함하는 사용자 정의 인증서로 PostgreSQL에 SSL을 구성합니다.
메시지: LOG: invalid CIDR mask in address
이는 postgresql['md5_auth_cidr_addresses']에 잘못된 형식의 주소가 있는 경우에 발생합니다.
2020-03-20_23:59:57.60499 LOG: invalid CIDR mask in address "***"
2020-03-20_23:59:57.60501 CONTEXT: line 74 of configuration file "/var/opt/gitlab/postgresql/data/pg_hba.conf"
이 문제를 해결하려면 /etc/gitlab/gitlab.rb의 postgresql['md5_auth_cidr_addresses']에서 IP 주소를 CIDR 형식으로 업데이트하여 (예: 10.0.0.1/32) 수정하십시오.
메시지: LOG: invalid IP mask "md5": Name or service not known
이는 postgresql['md5_auth_cidr_addresses']에 서브넷 마스크 없이 IP 주소를 추가했을 때 발생합니다.
2020-03-21_00:23:01.97353 LOG: invalid IP mask "md5": Name or service not known
2020-03-21_00:23:01.97354 CONTEXT: line 75 of configuration file "/var/opt/gitlab/postgresql/data/pg_hba.conf"
이 문제를 해결하려면 /etc/gitlab/gitlab.rb의 postgresql['md5_auth_cidr_addresses']에 CIDR 형식을 준수하도록(IP 주소에 서브넷 마스크를 추가하여) 업데이트하십시오 (예: 10.0.0.1/32).
메시지: gitlab-ctl replicate-geo-database실행시 gitlabhq_production 데이터베이스에서 데이터를 찾음
이는 projects 테이블에서 데이터가 감지되면 발생합니다. 하나 이상의 프로젝트가 감지되면 작업이 중단되어 실수로 데이터 손실을 방지합니다. 이 메시지를 우회하려면 명령에 --force 옵션을 전달하십시오.
GitLab 13.4에서 GitLab이 처음 설치될 때 시드 프로젝트가 추가됩니다. 이로 인해 기존 Geo 보조 사이트에서도 --force를 전달하는 것이 필요합니다. 데이터베이스를 확인할 때 시드 프로젝트를 고려하는 이슈가 있습니다.
메시지: FATAL: could not map anonymous shared memory: Cannot allocate memory
이 메시지가 표시되면 보조 사이트의 PostgreSQL이 사용 가능한 메모리보다 높은 메모리를 요청하는 경우입니다. 이 문제를 추적하는 이슈가 있습니다.
Linux 패키지 설치의 Patroni 로그(위치: /var/log/gitlab/patroni/current)에서의 예제 오류 메시지입니다:
2023-11-21_23:55:18.63727 FATAL: could not map anonymous shared memory: Cannot allocate memory
2023-11-21_23:55:18.63729 HINT: 의미하는 대로, PostgreSQL이 공유 메모리 세그먼트에 대한 요청이 사용 가능한 메모리, 스왑 공간 또는 대형 페이지를 초과했을 때 이 오류가 발생합니다. 요청 크기를 줄이려면(현재 17035526144 바이트), shared_buffers 또는 max_connections를 줄여 PostgreSQL의 공유 메모리 사용을 줄일 수 있습니다.
이 문제를 해결하기 위한 해결책은 보조 사이트의 PostgreSQL 노드에 사용 가능한 메모리를 증가시켜 primary 사이트의 PostgreSQL 노드의 메모리 요구 사항과 일치시키는 것입니다.
동기화 오류
모든 업로드 다시 확인(또는 확인된 SSF 데이터 유형)
- 기본 Geo 사이트의 GitLab 레일 노드에 SSH로 연결하십시오.
- Rails 콘솔을 엽니다.
- 모든 업로드를 “확인 대기”로 표시하십시오:
Upload.verification_state_table_class.each_batch do |relation|
relation.update_all(verification_state: 0)
end
- 이렇게 하면 기본 사이트에서 모든 업로드의 체크섬을 시작합니다.
- 기본이 레코드의 체크섬을 성공적으로 체크섬하면 모든 보조 사이트가 체크섬을 다시 계산하고 값이 동일한지 비교합니다.
Geo Self-Service Framework에서 처리되는 다른 모델에서도 유사한 작업을 수행할 수 있습니다:
LfsObjectMergeRequestDiffPackages::PackageFileTerraform::StateVersionSnippetRepositoryCi::PipelineArtifactPagesDeploymentUploadCi::JobArtifactCi::SecureFile
GroupWikiRepository는 검증이 구현되지 않았기 때문에 이전 디렉터리에 없습니다.
관리자 영역 UI에서 이 기능을 구현하기 위한 이슈가 있습니다.메시지: 동기화 실패 - 리포지터리 동기화 오류
다음 에러 메시지는 리포지터리를 동기화할 때 일관성 검사 오류를 나타냅니다:
동기화 실패 - 리포지터리 동기화 오류 [..] fatal: 패킹된 객체의 fsck 오류
이 오류는 여러 문제로 인해 발생할 수 있습니다. 예를 들어, 이메일 주소에 문제가 있는 경우:
리포지터리 동기화 오류: 13:fetch remote: "error: object <SHA>: badEmail: invalid author/committer line - bad email
fatal: 패킹된 객체의 fsck 오류
fatal: fetch-pack: invalid index-pack output
이 오류를 유발할 수 있는 또 다른 문제는 object <SHA>: hasDotgit: contains '.git'입니다. 모든 리포지터리 전체에 걸쳐 하나 이상의 문제가 있을 수 있으므로 특정 오류를 확인하세요.
두 번째 동기화 오류는 리포지터리 확인 문제로 인해 발생할 수도 있습니다:
리포지터리 동기화 오류: 13:Received RST_STREAM with error code 2.
이러한 오류는 실패한 모든 리포지터리를 즉시 동기화하여 확인할 수 있습니다.
일관성 오류를 일으키는 부정형 객체를 제거하려면 보통 옵션으로 리포지터리 기록을 재작성해야 합니다.
이러한 일관성 검사를 무시하려면 Geo 사이트의 보조에서 Gitaly를 다음과 같이 다시 구성하여 이러한 git fsck 문제를 무시할 수 있습니다.
다음 구성 예시:
- GitLab 16.0부터 필요한 새 구성 구조를 사용.
- 다섯 가지 일반적인 검사 실패를 무시합니다.
Gitaly 문서에 자세한 내용이 있으며 다른 Git 검사 실패 및 이전 버전의 GitLab에 대해 설명합니다.
gitaly['configuration'] = {
git: {
config: [
{ key: "fsck.duplicateEntries", value: "ignore" },
{ key: "fsck.badFilemode", value: "ignore" },
{ key: "fsck.missingEmail", value: "ignore" },
{ key: "fsck.badEmail", value: "ignore" },
{ key: "fsck.hasDotgit", value: "ignore" },
{ key: "fetch.fsck.duplicateEntries", value: "ignore" },
{ key: "fetch.fsck.badFilemode", value: "ignore" },
{ key: "fetch.fsck.missingEmail", value: "ignore" },
{ key: "fetch.fsck.badEmail", value: "ignore" },
{ key: "fetch.fsck.hasDotgit", value: "ignore" },
{ key: "receive.fsck.duplicateEntries", value: "ignore" },
{ key: "receive.fsck.badFilemode", value: "ignore" },
{ key: "receive.fsck.missingEmail", value: "ignore" },
{ key: "receive.fsck.badEmail", value: "ignore" },
{ key: "receive.fsck.hasDotgit", value: "ignore" },
],
},
}
GitLab 16.1과 이후에는 이러한 문제를 해결할 수 있는 향상된 기능이 포함되어 있습니다.
Gitaly 이슈 5625는 문제가 있는 커밋이 포함된 소스 리포지터리일지라도 Geo가 리포지터리를 복제하도록 보장하는 것을 제안합니다.
관련 오류 git 리포지터리 같지 않음
또한 다음 로그 메시지와 함께 동기화 실패 - 리포지터리 동기화 오류 오류 메시지를 받을 수 있습니다.
이 오류는 기대한 Geo 원격이 리포지터리의 .git/config 파일에 없음을 나타냅니다.
이를 해결하기 위해 다음을 수행합니다:
-
보조 Geo 사이트의 웹 인터페이스에 로그인합니다.
-
.git 폴더를 백업합니다.
-
선택 사항입니다. 일부 ID를 확인하여 실제로 알려진 Geo 복제 실패를 가진 프로젝트에 해당하는지 확인합니다. 다음 API 호출을 사용합니다:
curl --request GET --header "PRIVATE-TOKEN: <your_access_token>" "https://gitlab.example.com/api/v4/projects/<first_failed_geo_sync_ID>" -
레일스 콘솔에 들어가 다음을 실행합니다:
failed_geo_syncs = Geo::ProjectRegistry.failed.pluck(:id) failed_geo_syncs.each do |fgs| puts Geo::ProjectRegistry.failed.find(fgs).project_id end -
각 프로젝트의 Geo 관련 속성을 재설정하고 새로운 동기화를 실행하려면 다음 명령을 실행합니다:
failed_geo_syncs.each do |fgs| registry = Geo::ProjectRegistry.failed.find(fgs) registry.update(resync_repository: true, force_to_redownload_repository: false, repository_retry_count: 0) Geo::RepositorySyncService.new(registry.project).execute end
백필 중 실패
백필 중에는 실패가 백필 큐의 끝에서 재시도되므로, 이러한 실패는 백필이 완료된 이후에만 해소됩니다.
동기화 실패 메시지: “검증이 다음과 같이 실패함: 검증 중 오류: 파일이 체크섬을 생성할 수 없는 파일”
Geo 기본 사이트에 누락된 파일
GitLab 14.5 이전에는 Geo 기본 사이트에서 누락된 특정 데이터 유형은 Geo 이차 사이트에서 “동기화됨”으로 표시되었습니다. 이는 Geo 이차 사이트의 관점에서 상태가 기본 사이트와 일치하고 이차 사이트에서 더 이상 할 일이 없다는 것을 나타냅니다.
이차 사이트는 정기적으로 이러한 파일을 다시 동기화하려고 시도했습니다. “검증” 기능을 사용하여:
- 파일이 존재하지 않기 때문에 검증에 실패합니다.
- 파일이 “동기화 실패”로 표시됩니다.
- 동기화가 재시도됩니다.
- 파일이 “동기화 성공”으로 표시됩니다.
- 파일이 “검증 필요”로 표시됩니다.
- 파일이 다시 기본 사이트에서 사용 가능해질 때까지 반복됩니다.
다양한 백그라운드 작업에 의해 레지스트리 항목이 논리적으로 루프를 통해 이동하기 때문에 이를 해결하기 위한 과정은 혼란스러울 수 있습니다. 또한 last_sync_failure 및 verification_failure은 “동기화 성공” 후에 재검증되기 전에 비어 있습니다.
반복적으로 동기화 실패와 번갈아가며 증가하는 성공이 감소하는 것을 보게 된다면, 이는 기본 사이트에서 파일이 누락되었을 가능성이 큽니다. 이를 확인하려면 이차 사이트의 geo.log에서 계속 동일한 파일에 영향을 미치는 File is not checksummable를 검색하면 됩니다.
이 문제를 확인한 후, 기본 사이트의 파일을 수정해야 합니다. 일부 가능한 원인:
- NFS 공유가 마운트 해제됨.
- 디스크가 손상되거나 망가짐.
- 누군가가 의도하지 않게 파일이나 디렉터리를 삭제함.
- GitLab 애플리케이션의 버그:
- 파일이 옮겨져야 하는데 옮겨지지 않았음.
- 파일이 옮겨지지 말아야 하는데 옮겨짐.
- 코드에서 잘못된 경로가 생성됨.
- 비 원자적 백업이 복원됨.
- 서비스 또는 서버 또는 네트워크 인프라가 사용 중에 중단/재시작됨.
적절한 조치는 때때로 원인에 따라 달라집니다. 예를 들어 NFS 공유를 다시 마운트할 수 있습니다. 종종 근본적인 원인이 명백하지 않거나 발견할 가치가 없을 수 있습니다. 정기적인 백업이 있다면 그것을 통해 파일을 가져오는 것이 빠를 수 있습니다.
경우에 따라 파일이 낮은 가치로 판단되어 레코드를 삭제하는 것이 좋을 수 있습니다.
Geo 자체가 기본 사이트에서 누락된 파일에 대한 훌륭한 완화 조치입니다. 기본 사이트에서 파일이 사라지지만 이미 이차 사이트로 동기화된 경우 이차 사이트의 파일을 가져올 수 있습니다. 이런 경우에는 File is not checksummable 오류 메시지가 Geo 이차 사이트에는 발생하지 않으며 기본 사이트만이 이 오류 메시지를 기록합니다.
이 문제는 GitLab 14.6을 통해 다음 데이터 유형에만 영향을 미칩니다:
| 데이터 유형 | 버전부터 |
|---|---|
| Package registry | 13.10 |
| CI Pipeline Artifacts | 13.11 |
| Terraform State Versions | 13.12 |
| Infrastructure Registry (GitLab 15.11부터 Terraform Module Registry로 이름 변경) | 14.0 |
| External MR diffs | 14.6 |
| LFS Objects | 14.6 |
| Pages Deployments | 14.6 |
| Uploads | 14.6 |
| CI Job Artifacts | 14.6 |
GitLab 14.7부터 기본 사이트에서 누락된 파일은 이제 동기화 실패로 처리됩니다
Geo가 데이터 손실 위험을 명백하게 표면화하도록 만들기 때문입니다. 따라서 동기화/검증 루프가 바로 중단됩니다. last_sync_failure은 이제 The file is missing on the Geo primary site로 설정됩니다.
GitLab 관리 객체 리포지터리 복제 실패
GitLab 14.2부터 14.7까지 이 문제는 Geo에 영향을 미치며, GitLab 관리 객체 리포지터리 복제가 사용될 때 blob 객체 유형이 동기화에 실패합니다.
GitLab 14.2부터 검증 실패는 동기화 실패로 이어지며 이러한 객체들의 재동기화를 유발합니다.
검증은 객체 리포지터리에 저장된 파일에 대해 구현되지 않았기 때문에(자세한 내용은 이슈 13845를 참조) 객체 리포지터리에 저장된 모든 객체에 대해 지속적으로 실패하는 루프를 유발합니다.
각 객체를 동기화하고 검증을 하다가 오브젝트를 마킹하는 방식으로 이를 해결할 수 있지만, 주의해야 할 점은 기본 사이트에서 누락된 객체와도 마킹될 수 있다는 것입니다.
이를 위해 Rails 콘솔에 진입하여 다음을 실행하세요:
Gitlab::Geo.verification_enabled_replicator_classes.each do |klass|
updated = klass.registry_class.failed.where(last_sync_failure: "Verification failed with: Error during verification: File is not checksummable").update_all(verification_checksum: '0000000000000000000000000000000000000000', verification_state: 2, verification_failure: nil, verification_retry_at: nil, state: 2, last_sync_failure: nil, retry_at: nil, verification_retry_count: 0, retry_count: 0)
pp "Updated #{updated} #{klass.replicable_name_plural}"
end
메시지: curl 18 transfer closed with outstanding read data remaining & fetch-pack: unexpected disconnect while reading sideband packet
불안정한 네트워크 환경은 기본 사이트에서 대량 리포지터리 데이터를 가져올 때 Gitaly가 실패할 수 있습니다. 기존 GitLab 사이트 간에 리포지터리를 처음부터 복제해야 하는 경우 이러한 문제가 발생할 가능성이 높습니다.
Geo는 여러 번 재시도하지만, 네트워크 방해로 인해 전송이 일관되게 중단된 경우, git을 우회하여 rsync와 같은 대안적인 방법을 사용하여 해당 리포지터리의 초기 복사본을 생성할 수 있습니다.
각 실패하는 리포지터리를 개별적으로 전송하고 각 전송 후 일관성을 확인하는 것이 좋습니다. 단일 대상 rsync 지침을 따라 기본 사이트에서 이차 사이트로 각 영향을 받는 리포지터리를 전송하세요.
프로젝트 또는 프로젝트 위키 리포지터리
리포지터리 확인 실패 찾기
Start a Rails console session 보조 Geo 사이트에서 더 많은 정보를 수집하십시오.
확인 실패한 리포지터리 수 확인
Geo::ProjectRegistry.verification_failed('repository').count
확인 실패한 리포지터리 찾기
Geo::ProjectRegistry.verification_failed('repository')
동기화에 실패한 리포지터리 찾기
Geo::ProjectRegistry.sync_failed('repository')
프로젝트 및 프로젝트 위키 리포지터리 재동기화
보조 Geo 사이트에서 다음 변경 사항을 수행하려면 Start a Rails console session을 시작하십시오.
모든 리포지터리를 재동기화 대기열에 추가
이 명령을 실행하면 동기화가 Sidekiq에서 백그라운드로 처리됩니다.
Geo::ProjectRegistry.update_all(resync_repository: true, resync_wiki: true)
개별 리포지터리 지금 동기화
project = Project.find_by_full_path('<group/project>')
Geo::RepositorySyncService.new(project).execute
모든 동기화 실패한 리포지터리 지금 동기화
다음 스크립트:
- 현재 동기화에 실패한 모든 리포지터리를 반복합니다.
- 프로젝트 세부 정보 및 마지막 실패 이유를 표시합니다.
- 리포지터리를 재동기화하려고 시도합니다.
- 실패 시 실패 이유 및 이유를 알립니다.
- 완료에는 시간이 걸릴 수 있습니다. 각 리포지터리 확인이 완료되어야 결과를 보고합니다. 세션 시간이 초과될 경우
screen세션을 시작하거나 Rails runner 및nohup을 사용하여 프로세스를 계속 실행할 수 있는 조치를 취하세요.
Geo::ProjectRegistry.sync_failed('repository').find_each do |p|
begin
project = p.project
puts "#{project.full_path} | id: #{p.project_id} | last error: '#{p.last_repository_sync_failure}'"
Geo::RepositorySyncService.new(project).execute
rescue => e
puts "ID: #{p.project_id} failed: '#{e}'", e.backtrace.join("\n")
end
end ; nil
Geo 보조 사이트에서의 리포지터리 확인 실패 찾기
모든 프로젝트에 대해 활성화된 경우, Repository checks는 Geo 보조 사이트에서도 수행됩니다. 메타데이터는 Geo 추적 데이터베이스에 저장됩니다.
Geo 보조 사이트에서의 리포지터리 확인 실패는 반드시 복제 문제를 의미하는 것은 아닙니다. 다음은 이러한 실패를 해결하는 일반적인 방법입니다.
- 아래 언급된 영향을 받는 리포지터리 및 기록된 오류를 찾으세요.
- 특정
git fsck오류를 진단해 보세요. 가능한 오류 범위는 넓으며, 검색 엔진에서 찾아보세요. - 영향을 받는 리포지터리의 일반적인 기능을 테스트해 보세요. 보조에서 풀링, 파일 보기 등을 해보세요.
- 주 복제 사이트에서 리포지터리의 동일한
git fsck오류가 있는지 확인해 보세요. 장애 조치 계획이 있는 경우 주 응용 사이트가 보유한 정보가 보조 사이트에도 동일하게 있는 것이 중요합니다. 주 복제 사이트의 백업이 있는지 확인하고 계획된 장애 조치 지침을 따르세요. - 주 복제 사이트로 푸시하여 변경이 보조 사이트로 복제되는지 확인하세요.
- 자동으로 복제가 작동하지 않는다면 리포지터리를 매뉴얼으로 동기화해 보세요.
Start a Rails console session 에서 다음과 같은 기본적인 문제 해결 단계를 시행하세요.
리포지터리 확인 실패한 리포지터리 수 가져오기
Geo::ProjectRegistry.where(last_repository_check_failed: true).count
확인 실패한 리포지터리 찾기
Geo::ProjectRegistry.where(last_repository_check_failed: true)
리포지터리 확인 실패한 리포지터리 재확인
이 명령을 실행하면 각 실패한 리포지터리에 대해 fsck가 실행됩니다.
Geo 보조 사이트에서 fsck Rake 명령을 사용하여 왜 리포지터리 확인이 실패하는지 이해할 수 있습니다.
Geo::ProjectRegistry.where(last_repository_check_failed: true).each do |pr|
RepositoryCheck::SingleRepositoryWorker.new.perform(pr.project_id)
end
PostgreSQL 이외의 복제 실패 수정
Admin > Geo > Sites 또는 Sync status Rake task에서 복제 실패를 발견하면 다음 일반적인 단계로 실패를 해결해 볼 수 있습니다.
- Geo가 실패를 자동으로 재시도합니다. 신규 실패 건이 적고 root 원인이 이미 해결되었거나 의심스러운 경우, 실패가 사라지기를 기다리십시오.
- 실패가 오래되었거나 여러 번 재시도가 이미 발생했으며 자동 재시도 간격이 실패 유형에 따라 최대 4시간까지 증가한 경우, root 원인이 이미 해결되었다고 의심된다면 매뉴얼으로 복제 또는 확인을 다시 시도할 수 있습니다.
- 실패가 지속된다면 다음 섹션을 사용하여 실패를 해결해 보세요.
매뉴얼으로 복제 또는 확인 재시도
Geo 데이터 유형은 하나 이상의 GitLab 기능에 필요한 특정 데이터 클래스로, Geo에서 보조 사이트로 복제됩니다.
다음과 같은 Geo 데이터 유형이 있습니다.
-
Blob 유형:
Ci::JobArtifactCi::PipelineArtifactCi::SecureFileLfsObjectMergeRequestDiffPackages::PackageFilePagesDeploymentTerraform::StateVersionUploadDependencyProxy::ManifestDependencyProxy::Blob
-
리포지터리 유형:
ContainerRepositoryRegistryDesignManagement::RepositoryProjectRepositoryProjectWikiRepositorySnippetRepositoryGroupWikiRepository
주요 클래스 유형은 Registry, Model 및 Replicator입니다. 이러한 클래스 중 하나의 인스턴스가 있는 경우 다른 인스턴스를 얻을 수 있습니다. 레지스트리 및 모델은 대부분 PostgreSQL DB 상태를 관리합니다. Replicator는 복제/확인하는 방법을 알고 있거나 서비스를 호출하여 실행할 수 있습니다.
model_record = Packages::PackageFile.last
model_record.replicator.registry.replicator.model_record # 이러한 메서드가 존재함을 보여주는 예시
이 모든 정보를 통해 다음을 할 수 있습니다:
개별 컴포넌트 재동기화 및 재확인
개별 항목을 강제로 재동기화 및 재확인할 수 있습니다
자체 서비스 프레임워크로 관리되는 모든 컴포넌트 유형에 대한 UI를 사용해서 수행할 수 있습니다.
보조 사이트에서 Admin > Geo > Replication을(를) 방문하세요.
그러나 이것이 작동하지 않는 경우, 동일한 작업을 Rails 콘솔을 사용하여 수행할 수 있습니다. 다음 섹션에서는 레코드들의 동기화 또는 확인을 동기적 또는 비동기적으로 일으키기 위해 내부 응용 프로그램 명령어를 사용하는 방법에 대해 설명합니다.
Rails 콘솔 세션을 시작하세요 다음 기본 문제 해결 단계를 취하기 위해 다음과 같이 Rails 콘솔 세션을 시작하세요:
-
Blob 유형용 (예:
Packages::PackageFile구성요소 사용)-
동기화에 실패한 레지스트리 레코드 찾기:
Geo::PackageFileRegistry.failed -
주요 사이트에서 누락된 레지스트리 레코드 찾기:
Geo::PackageFileRegistry.where(last_sync_failure: 'The file is missing on the Geo primary site') -
ID가 주어졌을 때 패키지 파일 동기화, 동기적으로 재동기화:
model_record = Packages::PackageFile.find(id) model_record.replicator.send(:download) -
레지스트리 ID가 주어졌을 때 패키지 파일 동기화, 동기적으로 재동기화:
registry = Geo::PackageFileRegistry.find(registry_id) registry.replicator.send(:download) -
레지스트리 ID가 주어졌을 때 패키지 파일 동기화, 비동기적으로 재동기화. GitLab 16.2 이후 구성요소는 다음과 같이 비동기적으로 복제될 수 있습니다:
registry = Geo::PackageFileRegistry.find(registry_id) registry.replicator.enqueue_sync -
레지스트리 ID가 주어졌을 때 패키지 파일 확인, 비동기적으로 재확인. GitLab 16.2 이후 구성요소는 다음과 같이 비동기적으로 재확인될 수 있습니다:
registry = Geo::PackageFileRegistry.find(registry_id) registry.replicator.verify_async
-
-
리포지터리 유형용 (예:
SnippetRepository구성요소 사용)-
ID가 주어졌을 때 스니펫 리포지터리 동기화, 동기적으로 재동기화:
model_record = Geo::SnippetRepositoryRegistry.find(id) model_record.replicator.sync_repository -
레지스트리 ID가 주어졌을 때 스니펫 리포지터리 동기화, 동기적으로 재동기화:
registry = Geo::SnippetRepositoryRegistry.find(registry_id) registry.replicator.sync_repository -
레지스트리 ID가 주어졌을 때 스니펫 리포지터리 동기화, 비동기적으로 재동기화. GitLab 16.2 이후 구성요소는 다음과 같이 비동기적으로 복제될 수 있습니다:
registry = Geo::SnippetRepositoryRegistry.find(registry_id) registry.replicator.enqueue_sync -
레지스트리 ID가 주어졌을 때 스니펫 리포지터리 확인, 비동기적으로 재확인. GitLab 16.2 이후 구성요소는 다음과 같이 비동기적으로 재확인될 수 있습니다:
registry = Geo::SnippetRepositoryRegistry.find(registry_id) registry.replicator.verify_async
-
여러 컴포넌트 재동기화 및 재확인
다음 섹션에서는 Rails 콘솔에서 내부 응용프로그램 명령어를 사용하여 대량 복제 또는 확인을 일으키는 방법에 대해 설명합니다.
모든 컴포넌트 재확인(또는 확인을 지원하는 모든 SSF 데이터 유형)
GitLab 16.4 및 이전 버전의 경우:
- 주요 Geo 사이트의 GitLab 레일 노드에 SSH로 연결합니다.
- Rails 콘솔을 엽니다.
-
모든 업로드를
대기 중인 확인으로 표시합니다:Upload.verification_state_table_class.each_batch do |relation| relation.update_all(verification_state: 0) - 이로 인해 주요 사이트에서 모든 업로드의 체크섬을 시작합니다.
- 주요 사이트에서 레코드의 체크섬이 성공적으로 확인되면 모든 보조 사이트가 체크섬을 다시 계산하고 값을 비교합니다.
다른 SSF 데이터 유형의 경우 위의 명령어에서 Upload를 원하는 모델 클래스로 대체하세요.
보조에서 Blob 파일 확인 매뉴얼으로
보조에서 모든 패키지 파일을 반복하여 데이터베이스에 저장된 verification_checksum(주요 사이트에서 가져온 값)을 확인하고 이 값을 보조에서 계산하여 일치 여부를 확인합니다. 이 작업은 UI에서 아무런 변경을 일으키지 않습니다.
GitLab 14.4 이상의 경우:
# 보조에서 실행
status = {}
Packages::PackageFile.find_each do |package_file|
primary_checksum = package_file.verification_checksum
secondary_checksum = Packages::PackageFile.sha256_hexdigest(package_file.file.path)
verification_status = (primary_checksum == secondary_checksum)
status[verification_status.to_s] ||= []
status[verification_status.to_s] << package_file.id
end
# 각 값을 받아본 횟수 카운트
status.keys.each {|key| puts "#{key} 카운트: #{status[key].count}"}
# 전체 출력 확인
status
GitLab 14.3 이전의 경우:
# 보조에서 실행
status = {}
Packages::PackageFile.find_each do |package_file|
primary_checksum = package_file.verification_checksum
secondary_checksum = Packages::PackageFile.hexdigest(package_file.file.path)
verification_status = (primary_checksum == secondary_checksum)
status[verification_status.to_s] ||= []
status[verification_status.to_s] << package_file.id
end
# 각 값을 받아본 횟수 카운트
status.keys.each {|key| puts "#{key} 카운트: #{status[key].count}"}
# 전체 출력 확인
status
주요 Geo 사이트에서 업로드 확인 실패
주요 Geo 사이트에서 업로드의 확인이 verification_checksum = nil 및 verification_failure = Error during verification: undefined method 'underscore' for NilClass:Class로 실패하는 경우, 이는 고아 상태의 업로드 때문일 수 있습니다. 업로드를 소유하고 있는 상위 레코드(업로드의 모델)가 어떤 이유로든 삭제되었지만 업로드 레코드는 여전히 존재합니다. 이러한 확인 실패는 잘못됐습니다.
주요 Geo 사이트의 geo.log 파일에서 이러한 오류를 찾을 수 있습니다.
모델 레코드가 누락되었는지 확인하기 위해 주요 Geo 사이트에서 Rake 작업을 실행할 수 있습니다:
sudo gitlab-rake gitlab:uploads:check
이러한 확인 실패를 없애려면 다음과 같은 스크립트를 Rails 콘솔에서 실행하여 주요 Geo 사이트의 업로드 레코드를 삭제할 수 있습니다:
# 확인 오류가 있는 업로드 찾기
# 또는 자신의 영향을 받는 ID로 편집
uploads = Geo::UploadState.where(
verification_checksum: nil,
verification_state: 3,
verification_failure: "Error during verification: undefined method `underscore' for NilClass:Class"
).pluck(:upload_id)
uploads_deleted = 0
begin
uploads.each do |upload|
u = Upload.find upload
rescue => e
puts "checking upload #{u.id} failed with #{e.message}"
else
uploads_deleted=uploads_deleted + 1
p u ### 삭제하기 전에 검증
# p u.destroy! ### 실제로 삭제하려면 주석 해제
end
end
p "#{uploads_deleted} 원격 객체가 삭제되었습니다."
HTTP 응답 코드 오류
보조 사이트가 Geo 프록시를 사용하여 502 오류를 반환하는 경우
보조 사이트를 위한 Geo 프록시가 활성화된 상태에서 보조 사이트 사용자 인터페이스가 502 오류를 반환하는 경우, 주 사이트에서 프록시된 응답 헤더가 너무 큰 경우가 있습니다.
다음 예와 유사한 NGINX 로그에서 오류를 확인하세요.
2022/01/26 00:02:13 [error] 26641#0: *829148 upstream sent too big header while reading response header from upstream, client: 10.0.2.2, server: geo.staging.gitlab.com, request: "POST /users/sign_in HTTP/2.0", upstream: "http://unix:/var/opt/gitlab/gitlab-workhorse/sockets/socket:/users/sign_in", host: "geo.staging.gitlab.com", referrer: "https://geo.staging.gitlab.com/users/sign_in"
이 문제를 해결하려면:
- 모든 보조 사이트의 웹 노드에서
/etc/gitlab.rb에nginx['proxy_custom_buffer_size'] = '8k'를 설정하세요. -
sudo gitlab-ctl reconfigure를 사용하여 보조를 다시 구성하세요.
이 오류가 계속 발생하는 경우 버퍼 크기를 추가로 늘려서, 위의 단계를 반복하고 8k 크기를 2배인 16k로 변경하세요.
Geo 관리 영역에서 건강 상태가 ‘알 수 없음’ 및 ‘상태 코드 401로 실패한 요청’으로 표시되는 경우
로드 밸런서를 사용하는 경우, 로드 밸런서의 URL이 로드 밸런서 뒤의 노드들의 /etc/gitlab/gitlab.rb에서 external_url로 설정되어 있는지 확인하세요.
주 사이트가 /admin/geo/replication/projects에 액세스할 때 500 오류가 반환되는 경우
기본 Geo 사이트에서 관리 > Geo > 복제 (또는 /admin/geo/replication/projects)로 이동하면 500 오류가 표시되지만, 동일한 링크를 확인해 보면 보조 사이트에서 정상적으로 작동합니다. 주 사이트의 production.log에 다음과 유사한 항목이 있습니다.
Geo::TrackingBase::SecondaryNotConfigured: Geo secondary database is not configured
from ee/app/models/geo/tracking_base.rb:26:in `connection'
[..]
from ee/app/views/admin/geo/projects/_all.html.haml:1
이 오류는 Geo가 Geo 추적 데이터베이스에서 레지스트리를 표시하려고 시도하기 때문에 발생하며, 이 데이터베이스는 주 사이트에는 존재하지 않습니다. (주 사이트에는 원래 프로젝트만 존재하고 복제된 프로젝트는 없으므로 추적 데이터베이스도 존재하지 않습니다).
보조 사이트가 400 오류 “요청 헤더 또는 쿠키가 너무 큼”을 반환하는 경우
이 오류는 주 사이트의 내부 URL이 잘못된 경우 발생할 수 있습니다.
예를 들어, 통합 URL을 사용하고 주 사이트의 내부 URL이 외부 URL과 동일한 경우 발생할 수 있습니다. 이는 보조 사이트가 요청을 주 사이트의 내부 URL로 프록시하는 경우 루프를 일으킵니다.
이 문제를 해결하려면 주 사이트의 내부 URL을 다음과 같이 설정하세요:
- 주 사이트에 방문하세요.
- 내부 URL을 설정하세요.
Geo 관리 영역에서 404 오류가 보조 사이트 반환하는 경우
가끔 sudo gitlab-rake gitlab:geo:check가 보조 사이트의 Rails 노드가 정상임을 나타내지만, 주 사이트의 웹 인터페이스의 Geo 관리 영역에서 보조 사이트에 대해 404 Not Found 오류 메시지가 반환될 수 있습니다.
이 문제를 해결하려면:
-
sudo gitlab-ctl restart를 사용하여 보조 사이트의 각 Rails, Sidekiq 및 Gitaly 노드를 다시 시작해 보세요. -
주 사이트에서 보조 사이트의 상태를 IPv6로 보내고 있는지 Sidekiq 노드의
/var/log/gitlab/gitlab-rails/geo.log를 확인해 보세요. 그렇다면/etc/hosts파일에 IPv4를 사용하여 주 사이트에 항목을 추가하세요. 그렇지 않으면 주 사이트에서 IPv6를 사용 설정하세요.
일반 오류 해결
이 섹션에서는 웹 인터페이스의 관리 영역에서 보고된 일반적인 오류 메시지와 해당 해결 방법을 문서로 정리합니다.
Geo 데이터베이스 구성 파일이 없음
GitLab이 database_geo.yml 구성 파일을 찾거나 액세스할 수 없습니다.
Linux 패키지 설치의 경우 파일은 /var/opt/gitlab/gitlab-rails/etc에 있어야 합니다. 해당 파일이 없거나 부정한 변경이 가해졌다면 sudo gitlab-ctl reconfigure를 실행하여 올바른 상태로 복원하세요.
이 경로가 원격 볼륨에 장착되어 있다면 볼륨 구성이 올바른 권한을 가지고 있는지 확인하세요.
기존 추적 데이터베이스를 재사용할 수 없음
Geo는 기존 추적 데이터베이스를 재사용할 수 없습니다.
Geo 보조 사이트 복제 재설정을 따라 새로운 보조를 사용하거나 보조 전체를 재설정하는 것이 가장 안전합니다.
보조를 재설정하지 않고 재사용하는 것은 위험할 수 있습니다. 왜냐하면 보조 사이트가 일부 Geo 이벤트를 놓칠 수 있기 때문입니다. 예를 들어 삭제된 이벤트를 놓칠 경우 보조 사이트에는 삭제해야 할 데이터가 영구히 남게 됩니다. 마찬가지로 데이터 위치를 물리적으로 이동시키는 이벤트를 놓칠 경우 데이터는 한 위치에 영구적으로 고아가 되어 다른 위치에는 누락됩니다. 이는 데이터 이동이 불필요하게 되도록 해싱 스토리지로 변경된 이유이기도 합니다. 또한 놓친 이벤트로 인해 다른 알 수 없는 문제가 발생할 수 있습니다.
이러한 위험 요소가 해당되지 않는 경우, 예를 들어 테스트 환경인 경우, 또는 Geo 사이트가 추가된 이후 메인 PostgreSQL 데이터베이스에 모든 Geo 이벤트가 여전히 있는 경우에는 이 건강 검사를 바로 넘길 수 있습니다:
-
마지막으로 처리된 이벤트 시간을 가져옵니다. 보조 사이트의 Rails 콘솔에서 다음을 실행하세요:
Geo::EventLogState.last.created_at.utc - 출력을 복사합니다. 예를 들어
2024-02-21 23:50:50.676918 UTC와 같이 복사합니다. -
보조 사이트의 생성 시간을 업데이트하여 더 오래된 것처럼 보이도록 합니다. 기본 사이트의 Rails 콘솔에서 다음을 실행하세요:
GeoNode.secondary_nodes.last.update_column(:created_at, DateTime.parse('2024-02-21 23:50:50.676918 UTC') - 1.second)이 명령은 영향을 받는 보조 사이트가 마지막에 생성된 사이트라고 가정합니다.
-
Admin > Geo > Sites에서 보조 사이트의 상태를 업데이트합니다. 보조 사이트의 Rails 콘솔에서 다음을 실행하세요:
Geo::MetricsUpdateWorker.new.perform - 보조 사이트가 정상적으로 나타나어야 합니다. 그렇지 않은 경우, 보조 사이트에서
gitlab-rake gitlab:geo:check를 실행하거나 보조 사이트를 다시 추가한 이후에 아직 그렇게 하지 않은 경우 Rails를 다시 시작해 보세요. - 누락된 또는 오래된 데이터를 동기화하려면 Admin > Geo > Sites로 이동하세요.
- 보조 사이트 아래에서 Replication Details를 선택하세요.
- 각 데이터 유형에 대해 모두 재확인을 선택하세요.
Geo 사이트에 쓰기 가능한 데이터베이스가 있어 기본 사이트와의 복제가 구성되지 않았음을 나타냄
이 오류 메시지는 Geo가 액세스할 것으로 예상하는 보조 사이트의 데이터베이스 레플리카에 문제가 있음을 나타냅니다. 이는 보통 다음 중 하나를 의미합니다:
- 지원되지 않는 복제 방법이 사용되었습니다(예: 논리적 복제).
- Geo 데이터베이스 복제 설정 지침이 올바르게 따르지 않았습니다.
- 데이터베이스 연결 정보가 잘못되었습니다. 즉,
/etc/gitlab/gitlab.rb파일에서 올바른 사용자를 지정하지 않은 것입니다.
Geo 보조 사이트에는 두 개의 별도 PostgreSQL 인스턴스가 필요합니다:
- 기본 사이트의 읽기 전용 레플리카.
- 레플리케이션 메타데이터를 보유하는 일반적인 쓰기 가능한 인스턴스. 즉, Geo 추적 데이터베이스입니다.
이 오류 메시지는 보조 사이트의 레플리카 데이터베이스가 구성되지 않았으며 복제가 중단된 것을 나타냅니다.
데이터베이스를 복원하고 복제를 계속하려면 다음 중 하나를 수행할 수 있습니다:
새로운 보조 사이트를 처음부터 설정하는 경우 Geo 클러스터에서 이전 사이트 제거도 수행해야 합니다.
Geo 사이트가 기본 사이트로부터 데이터베이스를 복제하는 것으로 보이지 않음
데이터베이스가 올바르게 복제되지 않는 데 가장 흔한 문제는 다음과 같습니다:
- 보조 사이트가 기본 사이트에 도달할 수 없음. 자격 증명 및 방화벽 규칙을 확인하세요.
- SSL 인증서 문제.
/etc/gitlab/gitlab-secrets.json파일을 기본 사이트에서 복사했는지 확인하세요. - 데이터베이스 저장 디스크가 가득 참.
- 데이터베이스 레플리케이션 슬롯이 잘못 구성됨.
- 데이터베이스가 레플리케이션 슬롯을 사용하지 않거나 다른 대안을 사용하지 않는 등으로 WAL 파일이 제거되어 따라잡을 수 없는 경우.
지원되는 구성을 위해 Geo 데이터베이스 복제 지침을 따르는지 확인하세요.
Geo 데이터베이스 버전 (…)이(가) 최신 마이그레이션(…)과(와) 일치하지 않음
리눅스 패키지 설치를 사용하는 경우, 업그레이드 중에 문제가 발생했을 수 있습니다. 다음을 수행할 수 있습니다:
-
sudo gitlab-ctl reconfigure를 실행합니다. - 루트로 보조 사이트에서
sudo gitlab-rake db:migrate:geo를 실행하여 데이터베이스 마이그레이션을 수동으로 트리거합니다.
GitLab에서 리포지터리의 100% 이상이 동기화되었다는 메시지가 표시됨
프로젝트 레지스트리에 고아 레코드가 있을 경우 발생할 수 있습니다. 이는 주기적으로 레지스트리 워커를 사용하여 정리되므로 일정 시간을 주어 자체 해결되기를 기다리세요.
primary 사이트의 external_url 값을 변경한 후 UI에서 Unhealthy로 나타난 보조 사이트
/etc/gitlab/gitlab.rb 파일에서 external_url 값을 업데이트하거나 프로토콜을 http에서 https로 변경한 경우, 보조 사이트가 Unhealthy로 표시될 수 있습니다. 또한 geo.log에서 다음과 같은 오류를 찾을 수도 있습니다:
"class": "Geo::NodeStatusRequestService",
...
"message": "Failed to Net::HTTP::Post to primary url: http://primary-site.gitlab.tld/api/v4/geo/status",
"error": "Failed to open TCP connection to <PRIMARY_IP_ADDRESS>:80 (Connection refused - connect(2) for \"<PRIMARY_ID_ADDRESS>\" port 80)"
이 경우 변경된 URL을 모든 사이트에서 업데이트하세요:
- 좌측 사이드바에서 관리 영역을 선택합니다.
- Geo > Sites를 선택합니다.
- URL을 변경하고 변경 사항을 저장합니다.
백업 중 ERROR: canceling statement due to conflict with recovery 메시지
Geo 보조에서 백업을 실행하는 것은 지원되지 않습니다.
보조에서 백업을 실행하는 경우 다음과 같은 오류 메시지가 발생할 수 있습니다:
Dumping PostgreSQL database gitlabhq_production ...
pg_dump: error: Dumping the contents of table "notes" failed: PQgetResult() failed.
pg_dump: error: Error message from server: ERROR: canceling statement due to conflict with recovery
DETAIL: User query might have needed to see row versions that must be removed.
pg_dump: error: The command was: COPY public.notes (id, note, [...], last_edited_at) TO stdout;
Geo 보조에서 GitLab 업그레이드 중 자동으로 데이터베이스 백업을 방지하려면 다음과 같이 빈 파일을 생성하세요:
sudo touch /etc/gitlab/skip-auto-backup
장애 조치 중 오류 수정 또는 보조를 기본 사이트로 전환 중입니다
다음은 장애 조치 중 또는 보조를 기본 사이트로 전환 중에 발생할 수 있는 가능한 오류 메시지와 해당 해결 전략입니다.
메시지: ActiveRecord::RecordInvalid: Validation failed: Name has already been taken
보조 사이트로 전환 중에 다음과 같은 오류 메시지가 발생할 수 있습니다:
Running gitlab-rake geo:set_secondary_as_primary...
rake aborted!
ActiveRecord::RecordInvalid: Validation failed: Name has already been taken
/opt/gitlab/embedded/service/gitlab-rails/ee/lib/tasks/geo.rake:236:in `block (3 levels) in <top (required)>'
/opt/gitlab/embedded/service/gitlab-rails/ee/lib/tasks/geo.rake:221:in `block (2 levels) in <top (required)>'
/opt/gitlab/embedded/bin/bundle:23:in `load'
/opt/gitlab/embedded/bin/bundle:23:in `<main>'
Tasks: TOP => geo:set_secondary_as_primary
(See full trace by running task with --trace)
You successfully promoted this node!
gitlab-rake geo:set_secondary_as_primary 또는 gitlab-ctl promote-to-primary-node을 실행하는 중에 이 메시지를 만나면 다음 중 하나를 실행하세요:
-
Rails 콘솔에 들어가 실행:
Rails.application.load_tasks; nil Gitlab::Geo.expire_cache! Rake::Task['geo:set_secondary_as_primary'].invoke -
안전하다면 GitLab 12.6.3 이상 버전으로 업그레이드하세요. 예를 들어, 장애 조치가 테스트였을 경우. 캐싱 관련 버그가 수정되었습니다.
메시지: NoMethodError: undefined method `secondary?' for nil:NilClass
보조 사이트로 전환 중에 다음과 같은 오류 메시지가 발생할 수 있습니다:
sudo gitlab-rake geo:set_secondary_as_primary
rake aborted!
NoMethodError: undefined method `secondary?' for nil:NilClass
/opt/gitlab/embedded/service/gitlab-rails/ee/lib/tasks/geo.rake:232:in `block (3 levels) in <top (required)>'
/opt/gitlab/embedded/service/gitlab-rails/ee/lib/tasks/geo.rake:221:in `block (2 levels) in <top (required)>'
/opt/gitlab/embedded/bin/bundle:23:in `load'
/opt/gitlab/embedded/bin/bundle:23:in `<main>'
Tasks: TOP => geo:set_secondary_as_primary
(See full trace by running task with --trace)
이 명령은 보조 사이트에서만 실행되도록 되어 있으며 이 오류 메시지는 주 사이트에서 이 명령을 실행하려고 시도했을 때 표시됩니다.
만료된 아티팩트
Geo 보조 사이트에 기본 사이트보다 더 많은 아티팩트가 있는 경우에 대비해 Rake task를 사용하여 고아 아티팩트 파일을 정리할 수 있습니다.
Geo 보조 사이트에서 이 명령은 디스크 상의 고아 파일에 관련된 모든 Geo 레지스트리 레코드를 정리합니다.
로그인 오류 수정
메시지: 이동 URI가 올바르지 않습니다
기본 사이트의 웹 인터페이스에 로그인할 수 있지만 보조 웹 인터페이스에 로그인하려고 하면 이 오류 메시지가 표시되면 Geo 사이트의 URL이 외부 URL과 일치하는지 확인해야 합니다.
기본 사이트에서:
- 왼쪽 사이드바에서 맨 아래쪽에 Admin Area를 선택하세요.
- Geo > Sites를 선택하세요.
- 해당하는 보조 사이트를 찾아 Edit을 선택하세요.
-
URL 필드가 Rails nodes of the secondary 사이트의
/etc/gitlab/gitlab.rb에서 찾은 값과 일치하는지 확인하세요.
SAML을 사용하여 보조 사이트에서 인증하는 경우 항상 주 사이트로 이동하는 문제
이 문제는 GitLab 15.1로 업그레이드할 때 보통 발생합니다. 이 문제를 해결하려면 단일 로그인으로 Geo에 SAML 구성을 참조하세요.
클라이언트 오류 수정
LFS HTTP(S) 클라이언트 요청으로 인한 권한 오류
2.4.2 이전 버전의 Git LFS를 실행 중인 경우 문제가 발생할 수 있습니다. 이 인증 문제에서 언급했듯이, 보조 사이트에서 주 사이트로 리디렉션되는 요청이 올바르게 Authorization 헤더를 보내지 않을 수 있습니다. 이는 무한한 Authorization <-> Redirect 루프 또는 권한 오류 메시지가 발생할 수 있습니다.
오류: Geo 보조에서 SSH로 푸시할 때 Net::ReadTimeout
Geo 보조 사이트에서 SSH를 통해 대형 리포지터리를 푸시하는 경우 시간 초과 오류가 발생할 수 있습니다. 이는 Rails가 60초의 기본 타임아웃을 가지고 있고, Geo 이슈에서 설명한 것과 같습니다.
현재 사용 가능한 해결책은:
- Geo 프록시가 활성화되지 않은 경우 Workhorse가 주 사이트로 요청을 프록시하거나 주 사이트로 리디렉션합니다.
- 주 사이트로 직접 푸시합니다.
예제 로그 (gitlab-shell.log):
Failed to contact primary https://primary.domain.com/namespace/push_test.git\\nError: Net::ReadTimeout\", \"result\":null}" code=500 method=POST pid=5483 url="http://127.0.0.1:3000/api/v4/geo/proxy_git_push_ssh/push"
Geo 사이트 간 OAuth 권한 수정
Geo 사이트를 업그레이드하는 동안, 인증에 OAuth만 사용하는 보조 사이트에 로그인할 수 없을 수 있습니다. 이 경우 기본 사이트에서 Rails 콘솔 세션을 시작하고 다음 단계를 수행하세요:
-
영향을 받는 노드를 찾기 위해 먼저 모든 Geo 노드를 나열하세요:
GeoNode.all -
ID를 지정하여 영향을 받는 Geo 노드를 수정하세요:
GeoNode.find(<id>).repair
부분 장애 복구
부분 장애는 일시적인 문제의 결과일 수 있습니다. 따라서 먼저 프로모션 명령을 다시 실행하십시오.
-
Secondary 사이트의 모든 Sidekiq, PostgreSQL, Gitaly 및 Rails 노드에 SSH로 연결하고 다음 명령 중 하나를 실행합니다:
-
Secondary 사이트를 프라이머리로 프로모션하려면:
sudo gitlab-ctl geo promote -
추가 확인 없이 Secondary 사이트를 프라이머리로 프로모션하려면:
sudo gitlab-ctl geo promote --force
-
- 이전에 Secondary 사이트에 사용했던 URL을 사용하여 새로 프로모션된 Primary 사이트에 연결할 수 있는지 확인합니다.
- 성공적이라면 Secondary 사이트가 이제 프라이머리 사이트로 프로모션됩니다.
위 단계가 성공적이지 않으면, 다음 단계를 진행하십시오:
-
Secondary 사이트의 모든 Sidekiq, PostgreSQL, Gitaly, 및 Rails 노드에 SSH로 연결하고 다음 작업을 수행합니다:
-
다음 내용으로
/etc/gitlab/gitlab-cluster.json파일을 생성합니다:{ "primary": true, "secondary": false } -
변경 사항이 적용되도록 GitLab을 다시 구성합니다:
sudo gitlab-ctl reconfigure
-
- 이전에 Secondary 사이트에 사용했던 URL을 사용하여 새로 프로모션된 Primary 사이트에 연결할 수 있는지 확인합니다.
- 성공적이면 Secondary 사이트가 이제 프라이머리 사이트로 프로모션됩니다.
데이터베이스 복제 지연의 원인 조사
sudo gitlab-rake geo:status 명령의 출력에서 데이터베이스 복제 지연이 시간이 지남에도 여전히 상당히 높음을 보인다면, 데이터베이스 복제 프로세스의 각 부분에 대한 지연 상태를 결정하기 위해 기본 노드에서 확인할 수 있습니다. 이러한 값들은 write_lag, flush_lag, replay_lag로 알려져 있습니다. 자세한 내용은 공식 포스트그리스 문서를 참조하십시오.
다음 명령을 primary Geo 노드의 데이터베이스에서 실행하여 관련 출력을 제공합니다:
gitlab-psql -xc 'SELECT write_lag,flush_lag,replay_lag FROM pg_stat_replication;'
-[ RECORD 1 ]---------------
write_lag | 00:00:00.072392
flush_lag | 00:00:00.108168
replay_lag | 00:00:00.108283
이러한 값 중 하나 이상이 상당히 높으면, 이는 문제를 나타낼 수 있으며 더 조사해야 합니다. 원인을 결정할 때, 다음 사항을 고려하십시오:
-
write_lag는 primary에서 전송된 WAL 바이트가 secondary로 수신된 후 아직 플러시되거나 적용되지 않은 시간을 나타냅니다. - 높은
write_lag값은 primary와 secondary 노드 간의 네트워크 성능 하락이나 충분하지 않은 네트워크 속도를 나타낼 수 있습니다. - 높은
flush_lag값은 secondary 노드의 저장 장치에 대한 성능이 저하되거나 최적이 아닌 디스크 I/O 성능을 나타낼 수 있습니다. - 높은
replay_lag값은 PostgreSQL에서 장기 실행되는 트랜잭션이나 CPU와 같은 필요한 리소스의 포화를 나타낼 수 있습니다. -
write_lag와flush_lag간의 시간 차이는 WAL 바이트가 기본 저장 시스템에 전송되었지만 이들이 플러시되지 않았음을 나타냅니다. 이 데이터는 아마도 영속적인 리포지터리에 완전히 기록되지 않았으며 아마도 일종의 휘발성 기록 캐시에 보관되었습니다. -
flush_lag와replay_lag간의 차이는 스토리지에 성공적으로 지속되었지만 데이터베이스 시스템에서 재생되지 못한 WAL 바이트를 나타냅니다.
Geo Secondary 사이트의 복제 재설정
Secondary 사이트가 손상된 상태로 되어 있고 복제 상태를 재설정하고 다시 처음부터 시작하려는 경우, 다음 단계를 수행하여 도와줄 수 있습니다:
-
Sidekiq 및 Geo LogCursor를 중지합니다.
Sidekiq를 우아하게 중지할 수 있지만, 새 작업을 받지 않고 현재 작업이 처리를 마칠 때까지 기다릴 수 있습니다.
처음 단계에서
kill -TSTP시그널을 보내고 모든 작업이 처리를 마친 후에SIGTERM을 보내십시오. 그렇지 않으면gitlab-ctl stop명령을 사용하십시오.gitlab-ctl status sidekiq # run: sidekiq: (pid 10180) <- 이것이 사용할 PID입니다 kill -TSTP 10180 # 올바른 PID로 변경 gitlab-ctl stop sidekiq gitlab-ctl stop geo-logcursorSidekiq 작업 처리가 완료될 때까지 Sidekiq 로그를 확인할 수 있습니다:
gitlab-ctl tail sidekiq -
리포지터리 저장 폴더의 이름을 변경하고 새로운 폴더를 생성합니다. 가능한 소품 디렉터리와 파일에 대해 걱정하지 않으려면, 이 단계를 건너뛸 수 있습니다.
mv /var/opt/gitlab/git-data/repositories /var/opt/gitlab/git-data/repositories.old mkdir -p /var/opt/gitlab/git-data/repositories chown git:git /var/opt/gitlab/git-data/repositories더 이상 필요하지 않다고 확인하면/var/opt/gitlab/git-data/repositories.old를 나중에 제거하고 디스크 공간을 절약할 수 있습니다. -
선택 사항. 다른 데이터 폴더의 이름을 변경하고 새로운 폴더를 생성합니다.
여전히 Primary 사이트에서 제거된 파일이 Secondary 사이트에 남아 있을 수 있습니다. 이 단계를 건너뛰면, 이러한 파일은 Geo Secondary 사이트에서 제거되지 않습니다.업로드된 모든 내용(파일 첨부, 아바타 또는 LFS 객체와 같은)은 다음 경로 중 하나의 하위 폴더에 저장됩니다:
/var/opt/gitlab/gitlab-rails/shared/var/opt/gitlab/gitlab-rails/uploads
모두의 이름을 변경하려면:
gitlab-ctl stop mv /var/opt/gitlab/gitlab-rails/shared /var/opt/gitlab/gitlab-rails/shared.old mkdir -p /var/opt/gitlab/gitlab-rails/shared mv /var/opt/gitlab/gitlab-rails/uploads /var/opt/gitlab/gitlab-rails/uploads.old mkdir -p /var/opt/gitlab/gitlab-rails/uploads gitlab-ctl start postgresql gitlab-ctl start geo-postgresql폴더를 다시 생성하고 권한 및 소유권이 올바른지 확인하도록 구성을 다시 합니다:
gitlab-ctl reconfigure -
추적 데이터베이스를 재설정합니다.
선택 단계 3을 건너 뛰었다면,geo-postgresql및postgresql서비스가 실행 중인지 확인하십시오.gitlab-rake db:drop:geo DISABLE_DATABASE_ENVIRONMENT_CHECK=1 # Secondary 앱 노드에서 gitlab-ctl reconfigure # 추적 데이터베이스 노드에서 gitlab-rake db:migrate:geo # Secondary 앱 노드에서 -
이전에 중지한 서비스를 다시 시작합니다.
gitlab-ctl start
 도움말
도움말